The Domain Knowledge Software Bug That Hid for Months
A single quote row meant two physical shades, and the system counted it as one. How domain knowledge software bugs hide, and who catches them.
By Mike Hodgen
The Order That Didn't Add Up
The owner of a window-treatment manufacturer was reviewing a single order when something caught his eye. Order 4xxx. The controls count looked short. Not wildly off. Just one control missing on one assembly. The kind of thing most people would shrug at and move on.
He didn't move on. And that one missing control is how we found one of the most expensive domain knowledge software bugs I've ever traced.
Here's what makes this story worth telling. There was no crash. No error log. No red banner. No exception thrown anywhere in the system. The software ran perfectly. It produced clean, confident, completely wrong numbers, and it had been doing it for months.
Every dual-shade order they had ever quoted was undercounting hardware. Bottom rails, tubes, brackets, controls, motors. All short. Not on a few orders. On every single dual-shade order in the system's history.
This is the part that should make any CEO running automated software a little uncomfortable. The dangerous bugs don't announce themselves. A bug that crashes gets fixed in an afternoon because everyone sees it. A bug that produces plausible-looking numbers can run your business into the ground quietly, one undercounted order at a time, while every dashboard tells you everything is fine.
The software wasn't broken in any way a developer would recognize. It did exactly what it was told. The problem was that what it had been told didn't match what the data actually meant in the real world.
That gap, between what the code assumes and what the business knows, is where the worst bugs live. And it took someone who knew window treatments to even suspect it was there.
How the Data Lied: One Row, Two Shades
The coupled dual shade problem
To understand the bug, you have to understand the product. Not the code. The product.
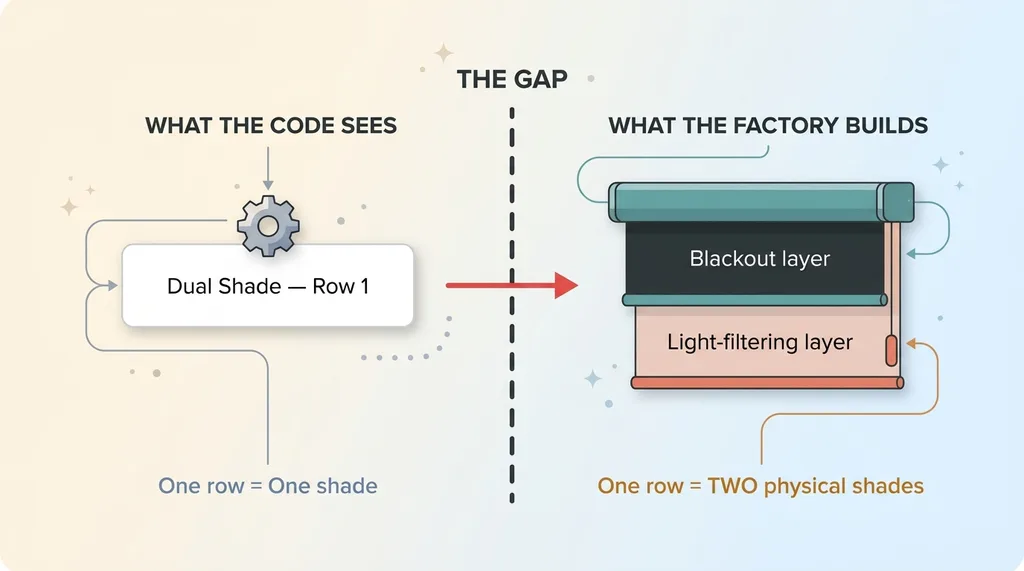 One row, two shades: the data-to-reality mismatch
One row, two shades: the data-to-reality mismatch
In window treatments, a "dual shade" is two physical shades coupled together on one assembly. Think a blackout layer for blocking light and a light-filtering layer for softening it, both mounted on the same headrail and operated as one unit. The customer sees one window covering. The factory has to build two complete shades.
That distinction is everything.
The quoting export encoded a dual shade as a single row. One line in the spreadsheet. To the software parsing that export, one row meant one shade. Physically, one row meant two shades. The data and the reality disagreed, and nobody had ever told the code about it.
Why the parser believed the data
The parser had no reason to doubt what it was reading. One row, one shade. That's a perfectly reasonable assumption for anyone who doesn't manufacture window treatments. It's the obvious reading.
But every per-shade calculation in the system inherited that wrong assumption. And these systems aggregate a lot per shade.
Each physical shade needs its own hardware:
- Bottom rails (one per physical shade)
- Tubes
- Fascia
- Brackets
- Controls
- Motors
- End caps
Every one of those gets counted per physical shade, not per row. So when a dual order came through as a single row, the bill of materials generated exactly half the hardware that order actually required.
Half the bottom rails. Half the tubes. Half the controls. The factory was being told to build two-shade assemblies with one shade's worth of parts.
This is a bill of materials accuracy failure, and it's important to be precise about its cause. This was not a coding mistake. The math was correct. The aggregation logic was correct. The code did exactly what it was designed to do.
The data just lied. And the code believed it.
The Second Bug Hiding Behind the First
Once we started pulling the thread, a second problem showed up underneath the first one. This one was arguably worse.
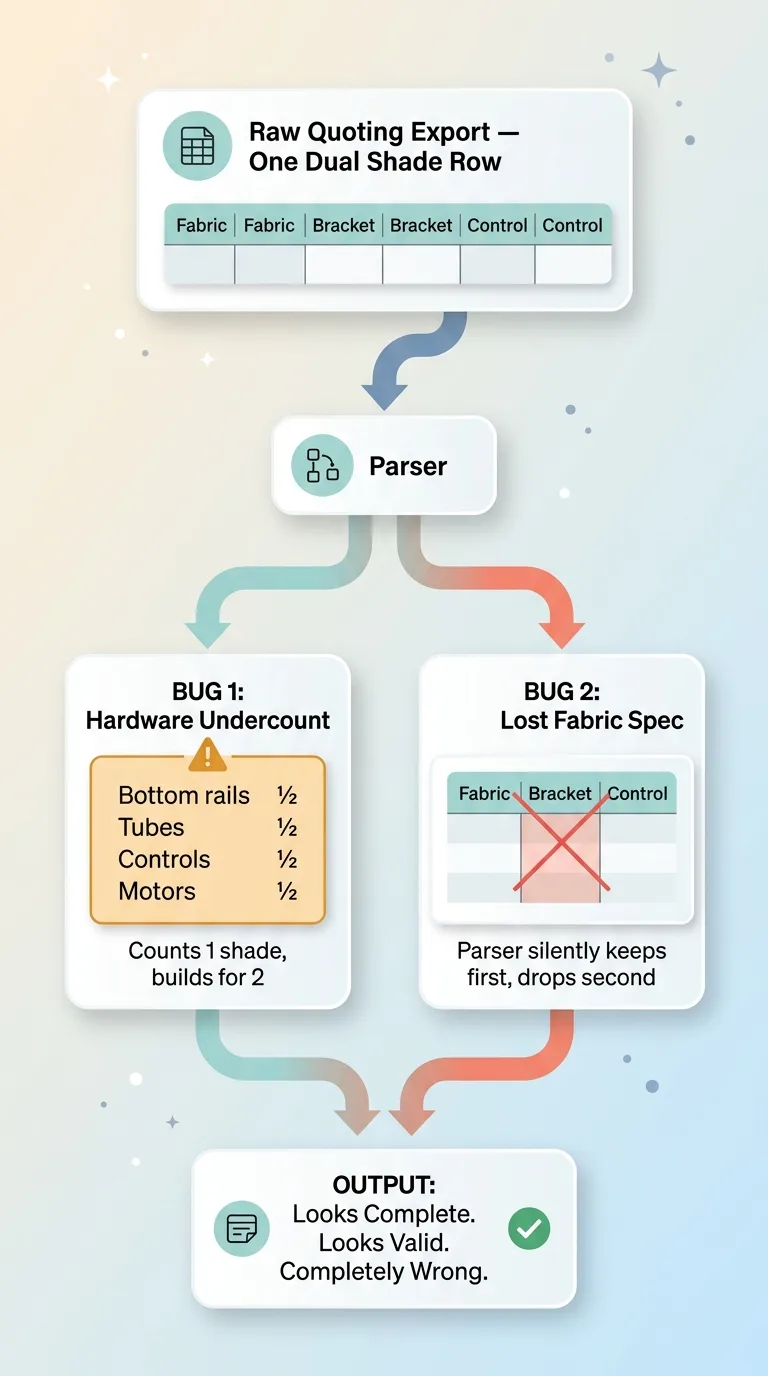 Two stacked silent bugs from one export row
Two stacked silent bugs from one export row
The second shade's fabric specification was being lost entirely.
Here's how. The raw export didn't just cram a dual shade into one row count. It used duplicate column headers, one set of columns for each side of the dual assembly. So the spreadsheet had two "fabric" columns, two of several other fields, one set for each physical shade.
When the parser hit those duplicate headers, it did what most parsers do. It silently kept the first one and dropped the second. No warning. No flag. It just quietly discarded the second shade's entire fabric specification.
So now you have two silent data errors stacked on top of each other. The hardware was undercounted by half. And the second shade's fabric was missing completely from the parsed record.
Both invisible. Because the output still looked complete and valid.
This is the thing I want CEOs to sit with. A blank field would have been caught. A zero would have been caught. Somebody reviewing the order would have seen "fabric: ___" and asked what happened. An error message would have triggered an investigation.
Plausible-looking numbers are what slip through. The order had a fabric. It had a hardware count. Everything was populated. Everything looked done. The output passed every visual sniff test a human could throw at it.
Software that looks like it works is far more dangerous than software that obviously doesn't. The broken kind gets fixed. The "looks fine" kind quietly ships wrong orders for months until one owner counts the controls.
Why a Bug Like This Hides for Months
No error, no alert, no symptom
This bug had no signature. None.
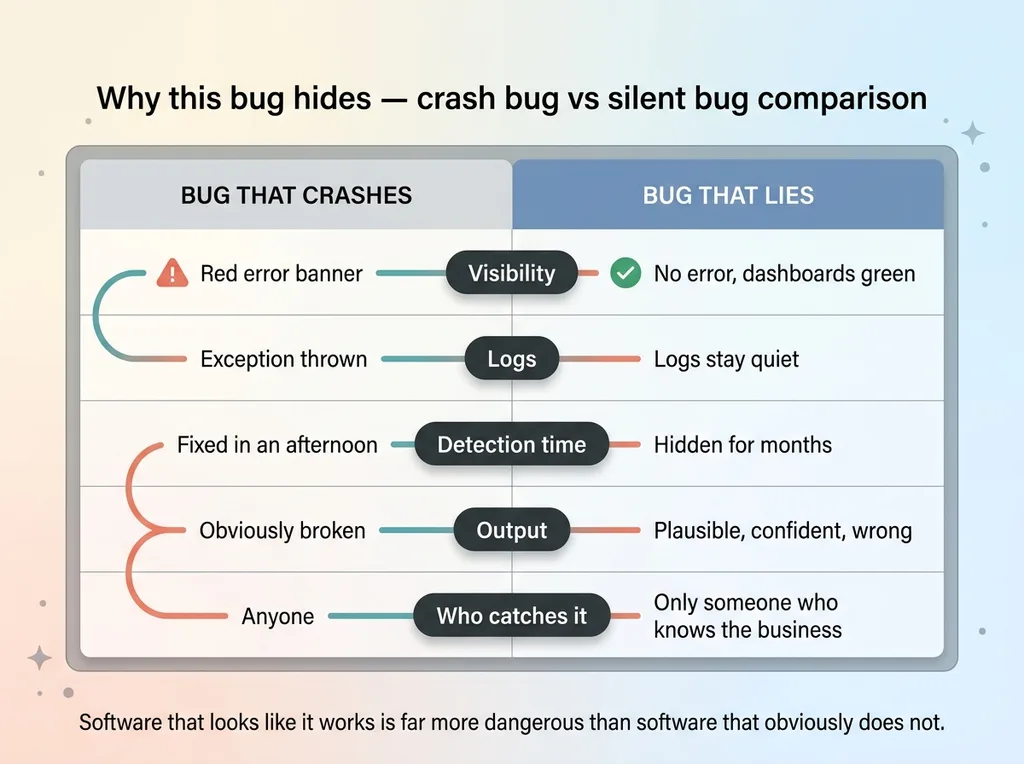 Why this bug hides, crash bug vs silent bug comparison
Why this bug hides, crash bug vs silent bug comparison
It didn't throw an exception. It didn't fail a unit test. It didn't return a zero or a null that something downstream would catch. It produced a real number that was simply half of what it should have been.
There was nothing to alert on, because from the software's perspective nothing went wrong. The code ran clean from input to output, every time.
You can't monitor for a bug that produces valid-looking results. Your error rate stays at zero. Your logs stay quiet. Your dashboards stay green. The system reports perfect health while shipping wrong numbers.
Why testing doesn't catch it
Here's why standard QA was never going to catch this.
Single-shade orders were the majority of the volume, and single-shade orders were perfectly correct. One row, one shade. The assumption held. So every spot check on a normal order passed. Every test against a standard order passed.
Only dual orders were wrong. And they were wrong by an amount that looked entirely plausible. Half the controls on a dual shade is still a believable number if you don't know the order is supposed to have two shades worth.
Standard testing verifies that code is correct against its own assumptions. This code was correct against its own assumptions. The unit tests would have passed because the tests encoded the same wrong belief the code did. You can't test your way out of a bad premise.
The bug lived in the gap between what the data meant in the real world and what the code assumed it meant. That gap is invisible to the code, invisible to the tests, and invisible to anyone reviewing output who doesn't know the product.
This is why most AI projects quietly fail. Not with a crash. With confident, wrong output that nobody questions.
This is the defining property of domain knowledge software bugs. They don't require better code or more tests. They require someone who knows the business well enough to look at a plausible number and say, wait, that's not right.
The Fix: Counting Physical Shades, Not Rows
An effective shade count multiplier
The fix itself was small. That's almost always true with these bugs. Finding it is the hard part. Fixing it is an afternoon.
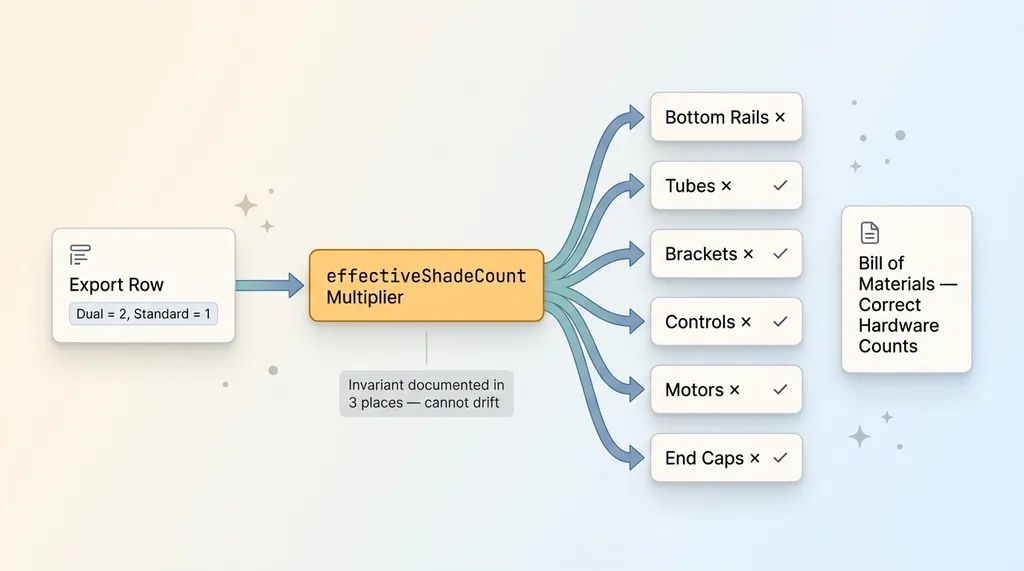 The fix: effectiveShadeCount multiplier flowing through aggregators
The fix: effectiveShadeCount multiplier flowing through aggregators
I introduced an effectiveShadeCount multiplier. A dual row counts as two physical shades. A standard row counts as one. One number that captures the real-world truth the data had been hiding.
Then I applied that multiplier across every aggregator in the system. Not just the controls count that tipped us off. Every hardware count, every material rollup, every per-shade calculation now reads the effective shade count instead of assuming one shade per row.
This is how the bill-of-materials math is supposed to behave. Every physical component traces back to a physical shade, and the count flows from there. It's the same principle behind the parametric BOM calculator I built, where the bill of materials is computed from real product parameters rather than from whatever the export happens to look like.
Reassembling the lost fabric
The second fix was reassembling the fabric that the parser had dropped. Instead of letting it silently discard the duplicate header, I read the raw row directly and mapped the second set of columns back to the second physical shade. The fabric that had been disappearing for months was now captured and assigned to the shade it belonged to.
Then the part that actually matters long term. I didn't just patch the bug. I documented the invariant.
The doubling rule, that a dual shade is two physical units, now lives explicitly in three places in the system. And the rule is written down: any new aggregator added to the system must apply the effective shade count. The next developer, or the next AI agent, can't quietly reintroduce the bug by adding a count that forgets the rule.
This matters because business rules drift. Someone adds a feature, writes a new aggregation, and the unwritten assumption is gone. So I encode the rule deterministically in the code rather than hoping everyone remembers it. This is the principle of letting the model judge and the code compute. The real-world meaning gets captured once, then the math runs on top of it the same way every time. No drift.
The fix was a multiplier and a remapping. The value was knowing it needed to exist.
Who Catches the Bug When AI Builds the Software
Here's the question every CEO should be asking right now. If AI writes my software, who catches the subtle bugs only someone who knows my business would notice?
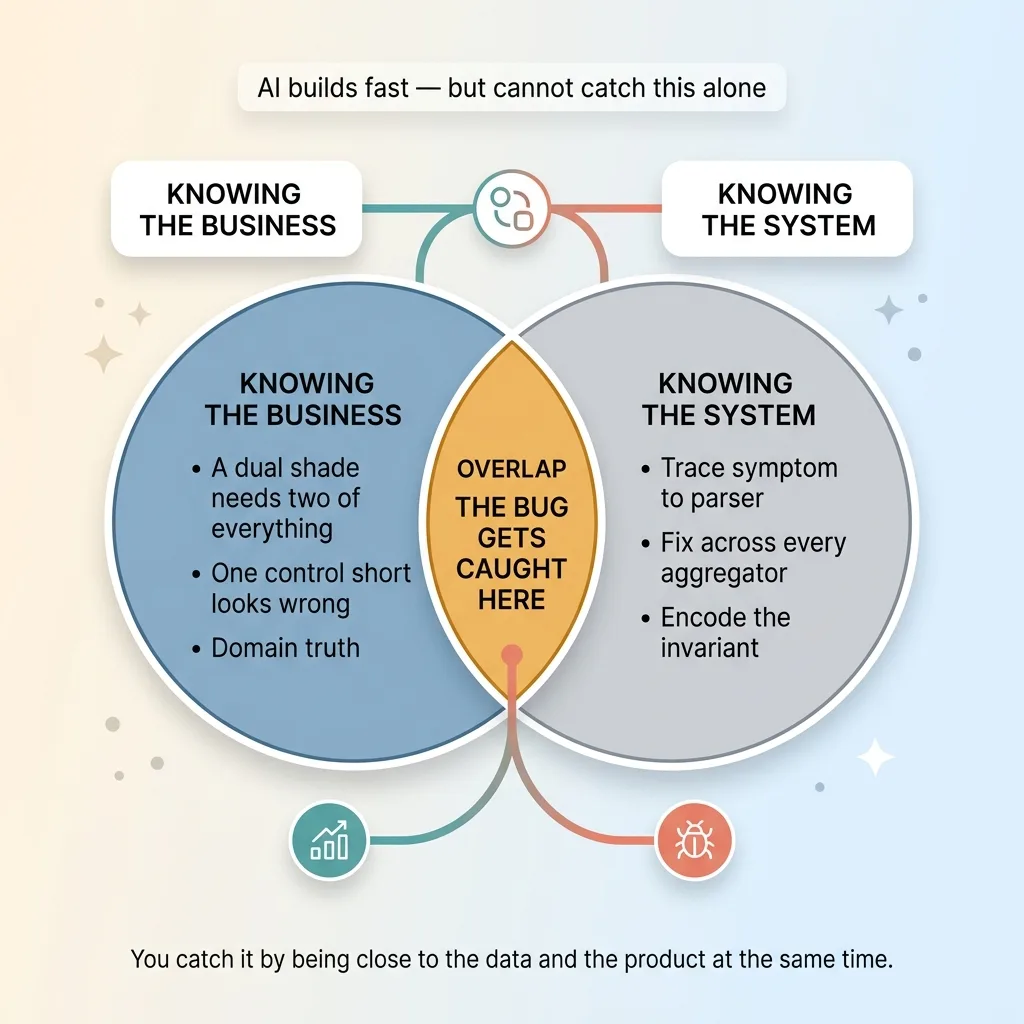 Two kinds of knowing meet to catch the bug
Two kinds of knowing meet to catch the bug
I'll give you the honest answer, because the honest answer is the whole point.
AI would not have caught this on its own. Neither would a generic developer who didn't understand window treatments. The AI built the parser correctly against a reasonable assumption: one row, one shade. That's a sensible default. Any competent developer would have written it the same way.
The assumption was wrong because nobody had encoded the real-world meaning of a dual shade. The code wasn't flawed. The premise was, and the premise came from a domain fact that no amount of clean coding would surface.
This is exactly where AI code domain expertise matters. The catch came from a human who understood the product. The owner noticed a controls count was off, because he builds these things and knows what a dual shade requires. Then it took someone who could connect that one-control symptom to the underlying data structure and fix it across every aggregator in the system.
That's two different kinds of knowing. Knowing the business, and knowing the system. The bug only gets caught where they meet.
AI accelerates the building enormously. I build faster with it than I ever could without it. But speed doesn't help if the foundation encodes a wrong assumption about your business. You still need someone who treats your domain as the source of truth and audits the system against reality, not against itself.
That's why I build the systems, not just advise on them. You can't catch a bug like this from a slide deck. You catch it by being close enough to the data and the product at the same time.
What This Means for Anyone Running on Automated Systems
Every automated system you run makes assumptions about your business that nobody wrote down.
Most of them are right. That's why the systems work at all. But the ones that are wrong don't fail loudly. They produce confident, plausible, wrong output for months until someone who knows the business looks twice and counts the controls.
This was a window-treatment manufacturer. But the pattern is universal. A quoting engine that misreads a product configuration. A pricing system that assumes every SKU behaves the same way. An inventory rollup that counts the wrong unit. Every one of these can run silently wrong while every dashboard says fine.
The work is not just building the software. Anyone can build software now. The work is three things. Auditing the system against how your business actually behaves. Encoding the invariants so they can't drift as the system grows. And keeping someone in the loop who treats domain knowledge as a first-class input, not an afterthought.
That last part is the hardest to buy and the easiest to skip. It's also the difference between software that looks like it works and software that actually does.
This is the kind of thing I do as a Chief AI Officer. I build the systems, and I stay close enough to the business to catch the bugs that only show up when the data lies. The silent data error that hides for months is exactly the failure mode I'm watching for, because I've seen what it costs.
If you're running on automated systems and you've never had someone audit them against how your business actually works, that's worth a conversation. Not a sales pitch. A conversation about where the wrong assumptions might be hiding.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call