The Ecommerce Brand Audit Engine I Run Before Any Client
How I score a new ecommerce client's business across 8 dimensions with a brand audit engine that pulls real Shopify data and ranks fixes by ROI.
By Mike Hodgen
Most Consultants Guess Where to Start. I Refuse To.
For years, onboarding a new ecommerce client looked the same for me as it did for everyone else in this business. You get access to the store admin, you poke around, you pull up a few reports, and within an hour you've formed an opinion about what's broken.
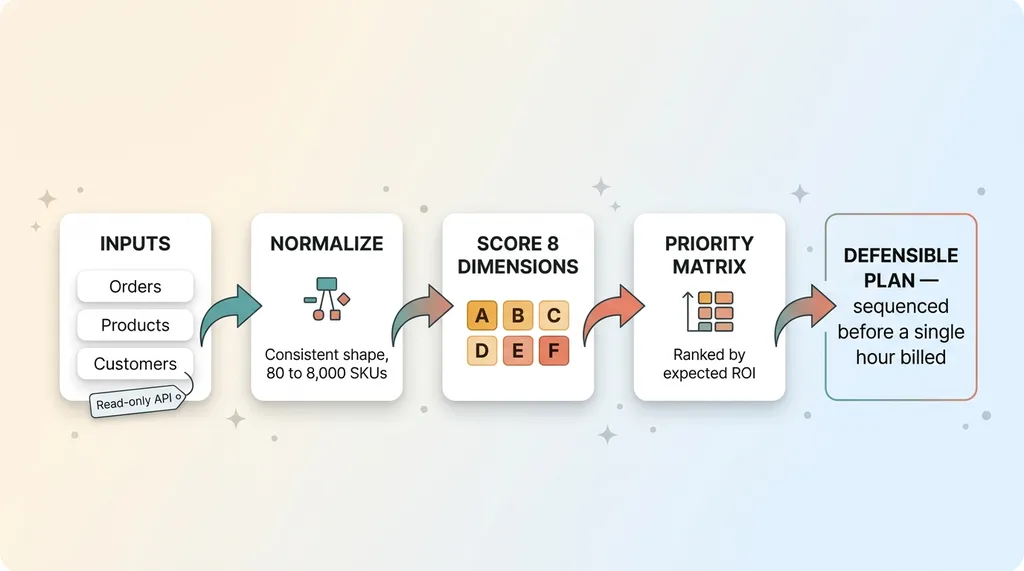 The end-to-end audit engine pipeline: from data ingestion to ranked plan
The end-to-end audit engine pipeline: from data ingestion to ranked plan
The problem is that opinion was shaped by whatever caught my eye first, not by what would actually move revenue. See a thin blog? Pitch content. Slow site? Pitch a speed fix. Whatever I happened to notice, and frankly whatever I happened to be good at selling, became the recommendation.
That's the dirty secret of most consulting engagements. When a CEO asks "how do you decide what to fix first?", the honest answer for most people in this field is "gut feel plus whatever's easiest to invoice."
I built something to kill that habit in my own work. It's an ecommerce brand audit engine that scores a store's real data across eight dimensions before I propose a single hour of work. No discovery-call vibes. No questionnaire. Just the numbers the business already has.
I'd rather start at the right end of the problem than the loudest one. The loudest problem and the most valuable problem are almost never the same thing, and the only way to tell them apart is to measure.
The rest of this article walks through exactly what the engine measures, how it turns those measurements into a ranked plan, and why it changes the buying conversation completely. By the end you'll understand why I won't quote a client work until the data has told me where to point it.
What the Engine Actually Ingests (Read-Only, Real Data)
The audit runs on three inputs: orders, products, and customers. That's it. Everything the engine scores comes from data the store already generates every single day.
Orders, products, customers
It pulls the full order history, the entire product catalog, and the complete customer record set through the store's API. Then it normalizes all of it into a consistent shape so the scoring logic can run the same way on every brand, whether they have 80 SKUs or 8,000.
Take a premium leather-goods brand as an example. The engine ingests their order history going back as far as the data allows, every product with its sales and margin signals, and every customer with their purchase timeline. Within minutes it has a complete picture that the owner has never actually looked at all at once.
That last part matters. Most store owners look at this data one slice at a time. Revenue this month. Top products this week. A churn report when someone remembers to ask for it. They almost never see all eight dimensions of their business scored side by side.
Read-only API access only
Here's the part skeptical buyers care about most: the engine uses read-only API access. No write permissions, ever. Nothing in your store changes during the audit. No products edited, no settings touched, no risk.
Granting a consultant read-only access is about as low-risk as it gets. And it means the diagnosis runs on your real numbers, not on what you remember to tell me on a sales call. People misremember their own business constantly. The data doesn't.
So the entire foundation of the audit is real, complete, and untouched. That's the only honest place to start.
The 8 Dimensions It Scores A Through F
The engine scores eight weighted dimensions, each getting a letter grade from A to F based on a set of underlying sub-metrics. Here's what each one actually looks at.
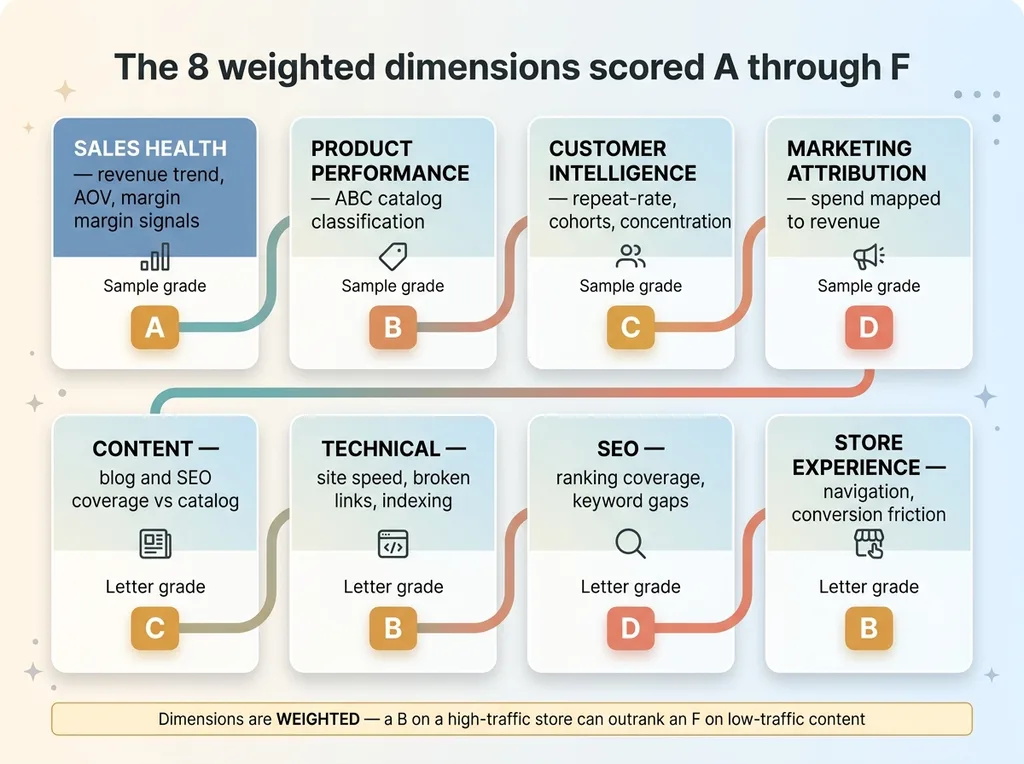 The 8 weighted dimensions scored A through F
The 8 weighted dimensions scored A through F
Sales health and product performance
Sales health covers revenue trend, average order value, and margin signals. Is revenue growing, flat, or quietly declining? Is AOV strong or are you discounting your way to volume? This is the heartbeat of the whole business.
Product performance is where dead weight gets exposed. The engine runs an ABC-style classification across the catalog to separate the SKUs carrying real revenue from the ones occupying shelf space and merchandising attention for nothing. On the leather-goods brand, this is the difference between knowing they sell bags and knowing which six products generate most of the money.
Customer intelligence and marketing attribution
Customer intelligence looks at repeat-rate, cohort behavior, and revenue concentration. Are buyers coming back, and if so, when? Is revenue dangerously concentrated in a small group of customers? Cohort patterns tell you whether the business is compounding or just churning through new buyers.
Marketing attribution asks one blunt question: does your spend map to revenue, or is it a black box? Plenty of brands spend real money on ads and have no clean line from dollar in to dollar out. The engine grades how traceable that connection actually is.
Content, technical, SEO, and store experience
Content measures blog and SEO content coverage against what the catalog and category actually warrant. Technical checks site speed, broken links, and indexing health, the plumbing that quietly costs conversions. SEO scores ranking coverage and keyword gaps, where the brand shows up and where it's invisible. Store experience evaluates navigation and conversion friction, the path from landing to checkout.
Now the important part: the dimensions are weighted. A B in store experience on a high-traffic store can matter more than an F in content, because that B touches far more revenue. The grades are never the deliverable. They're the raw input to the priority matrix, which is where the real decision gets made.
From Grades to a Priority Matrix Ranked by ROI
This is the part that answers the CEO's real doubt. Grades alone are useless. A scorecard full of letters tells you what's weak, but not what to do first, and those are completely different questions.
Why a low grade isn't automatically the first fix
The grades feed a priority matrix that ranks opportunities by expected ROI, not by how bad the grade is. A dimension scoring an F that touches almost no revenue will rank below a C that gates a major revenue lever. The worst grade is almost never the right first move.
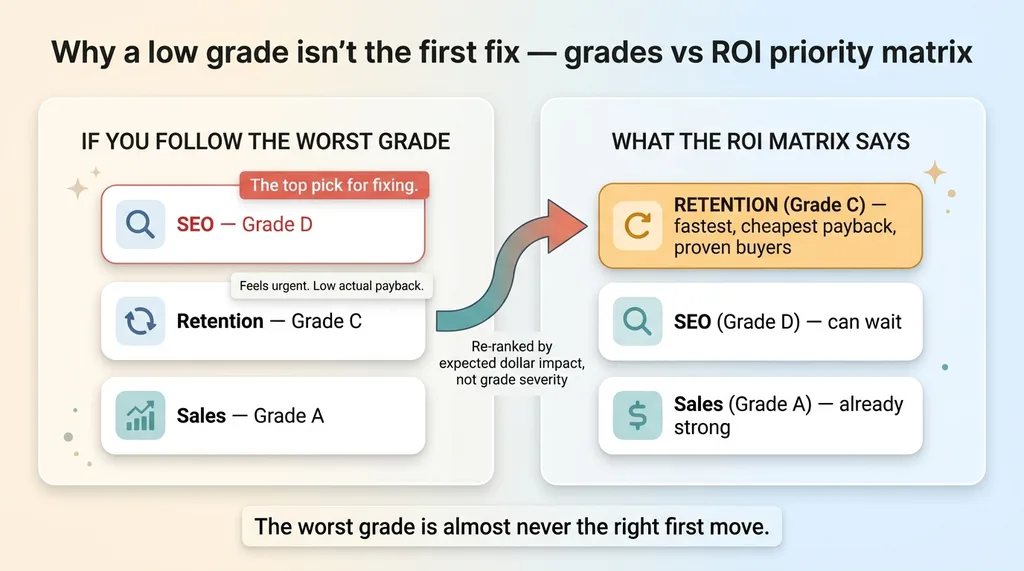 Why a low grade isn't the first fix, grades vs ROI priority matrix
Why a low grade isn't the first fix, grades vs ROI priority matrix
Walk through the leather-goods brand. Say their SEO grade comes back poor, a D. The instinct is to attack it, because a D feels urgent. But the matrix says no. Their product performance is strong, their customers love the goods, and their repeat-rate is mediocre because nobody is re-engaging a base that's already proven it will buy.
So the fastest win isn't SEO. It's repeat-rate. Re-activating existing buyers on a brand with great products and weak retention pays back faster and cheaper than clawing up the search rankings. The F-graded SEO can wait. The C-graded retention opportunity comes first because the math says so.
Revenue and repeat-rate views
The matrix outputs a ranked list along with revenue and repeat-rate views, so the CEO sees the actual math behind "fix this first." Not my opinion. The expected dollar impact of each move, sorted.
That ranked sequence becomes the plan. And because every fix starts with a measured baseline, you can track the ROI of every fix after the fact instead of taking my word that the work paid off.
The whole point is this: I commit to a sequence of work that's defensible in numbers before I bill a single hour. If I can't show you why item one ranks above item two, I haven't earned the engagement.
Brand-Agnostic by Design: One Config File, One Isolated Database
The reason this audit is cheap and objective instead of a multi-week custom project is the architecture underneath it. The engine is the same for every client. Only the client-specific details change.
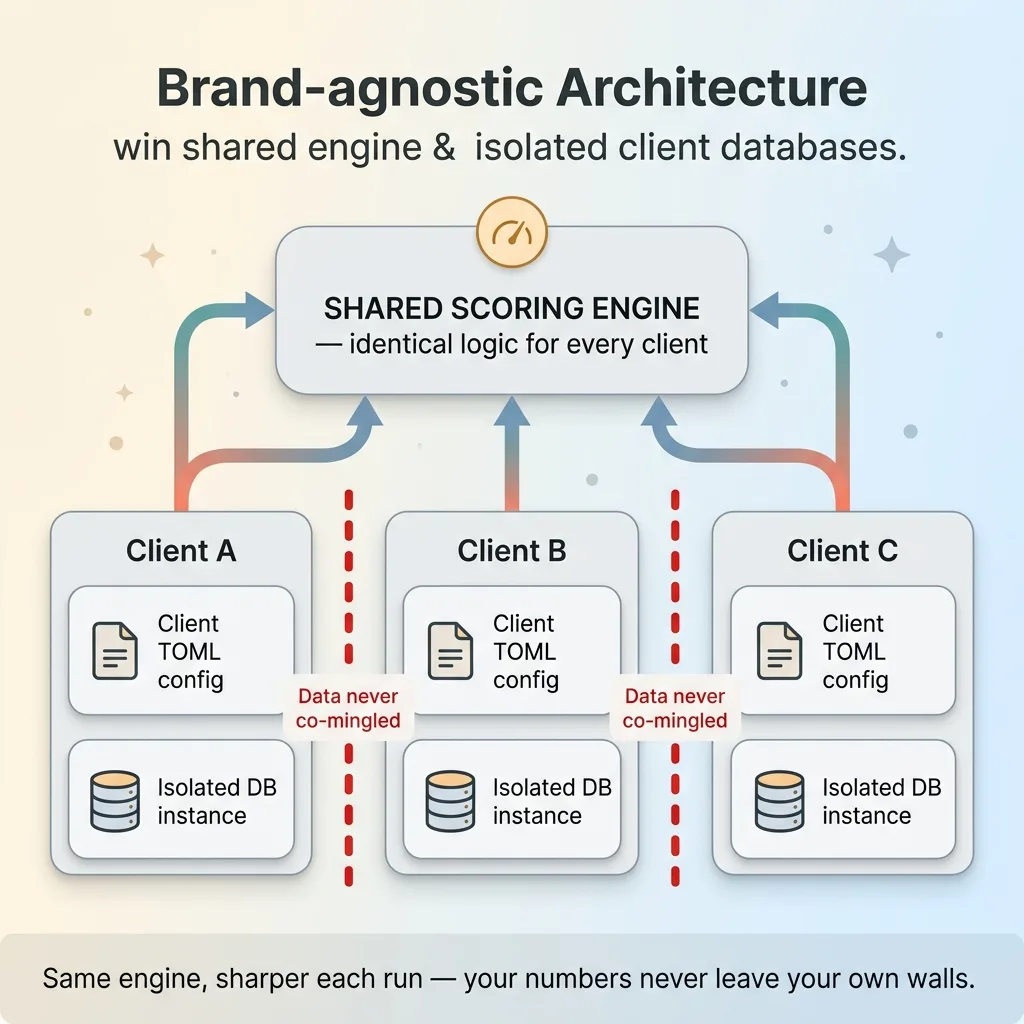 Brand-agnostic architecture: shared engine, isolated client databases
Brand-agnostic architecture: shared engine, isolated client databases
Each client is a TOML config
A new client is, mechanically, a TOML config file plus their own isolated database instance. The config defines the client's specifics, their catalog structure, their thresholds, their context. The scoring logic stays identical across every brand that runs through it.
That means I'm not reinventing a process for each engagement. You're not paying me to design an audit from scratch, you're paying for the result of an engine that's already run across multiple brands and gotten sharper each time. The logic improves with every client. The diagnosis gets faster and more accurate without getting more expensive.
Data is never co-mingled
No two clients' data ever touch. Each brand sits in its own isolated instance, separate from every other client and separate from my own brand's data. Every client gets their own isolated database by default, not as a premium add-on.
This matters for two reasons. First, your data sits alone, never pooled with competitors or strangers. Second, it makes onboarding fast and consistent, which is what keeps the audit affordable enough that it can be the starting point rather than the deliverable.
Repeatability is the whole trick. The shared engine is what lets the diagnosis be objective and cheap. The separated data is what keeps it safe. You get the benefit of a system refined across many brands while your numbers never leave your own walls.
What the Engine Doesn't Do (And Where Judgment Still Lives)
I'd be lying if I told you the engine runs the strategy. It doesn't. It scores and ranks. It does not decide what to actually build.
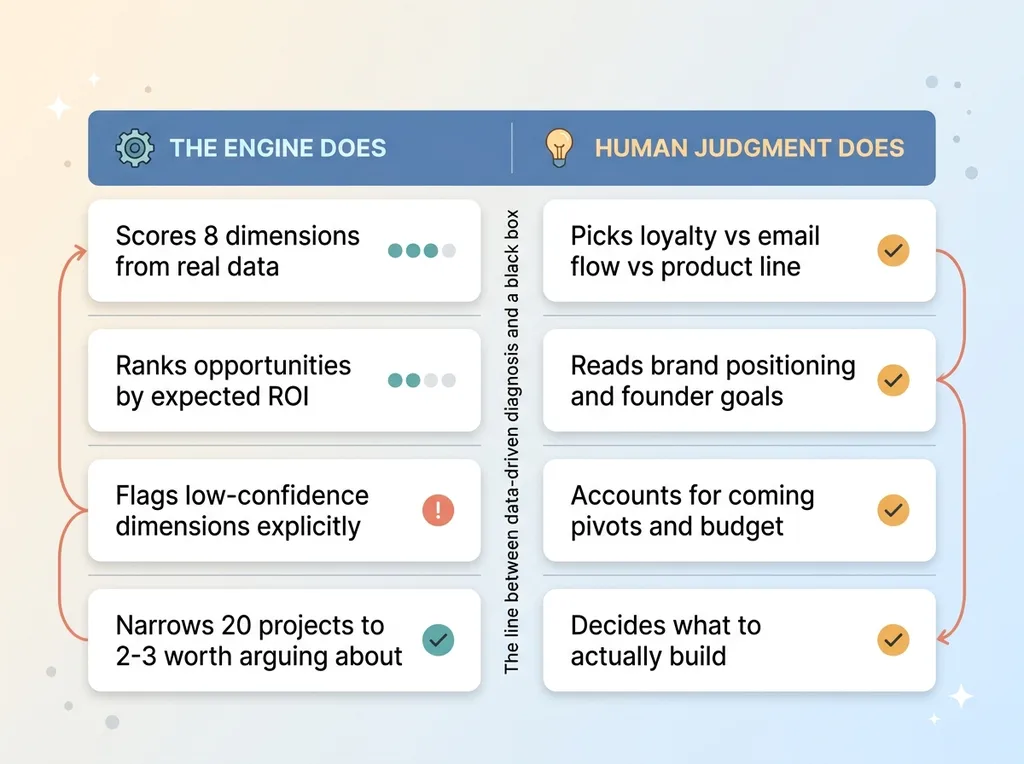 What the engine does vs where human judgment still lives
What the engine does vs where human judgment still lives
The engine can tell you repeat-rate is your highest-ROI lever with full confidence. What it cannot tell you is whether the right move is a loyalty program, a post-purchase email flow, or a product line extension that gives people a reason to come back. Three valid answers, all aimed at the same lever, and the right one depends on things the data doesn't contain.
That's where I come in. The numbers narrow the field from twenty possible projects down to the two or three worth arguing about. Then we have a real conversation about which one fits the business, the budget, and the team.
The engine also can't read intangibles. Brand positioning, the founder's actual goals, a pivot that's coming in six months. A score can't see any of that. If you're about to discontinue half your catalog, the product-performance grade is suddenly irrelevant, and only a human conversation surfaces that.
And here's the honest limitation: garbage in lowers confidence out. If your attribution is broken or your product tagging is a mess, some dimensions can't be scored cleanly. The engine doesn't paper over that. It flags low-confidence dimensions explicitly rather than pretending it knows.
That's the line between a data-driven diagnosis and a black-box score. A black box hands you a number and dares you to trust it. This hands you the math, shows you where it's confident, tells you where it isn't, and leaves the judgment to a person.
What This Means If You're About to Hire Someone for AI or Growth Work
Here's the takeaway if you're sitting on a decision about who to bring in. You shouldn't hire anyone who can't tell you, in numbers, what they'd fix first and why.
Most engagements start with discovery calls that produce opinions. Smart-sounding opinions, sometimes. But opinions shaped by whatever the consultant noticed first and is best at selling. You've probably been burned by exactly that.
This produces something different: a ranked, ROI-weighted plan built from your real data, before any commitment. The priority matrix decides the sequence, not my gut.
This is the same kind of system I run my own brand on, turned outward for clients. I don't recommend things I haven't already pressure-tested on my own revenue.
So start with the audit itself. It's low-commitment and read-only. Nothing in your store changes. The engine scores your eight dimensions, the matrix ranks the opportunities, and then you decide whether there's enough upside to actually work together.
Let the data make the case before you spend a dollar on the work. If the matrix says there's a six-figure lever sitting untouched, that's a conversation worth having. If it says you're already running tight, I'll tell you that too.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call