Self-Improving AI Agents: Closing the Learning Loop
Most 'AI that learns' never reconciles predictions with outcomes. Here's how I built self-improving AI agents that grade their own decisions 72 hours later.
By Mike Hodgen
The Lie Inside Every 'AI That Learns Over Time'
Every AI vendor says the same thing. "Our system learns over time. It gets smarter the more you use it." It sounds great. It usually means nothing.
 Recording vs Learning, Disconnected Logs vs Closed Loop
Recording vs Learning, Disconnected Logs vs Closed Loop
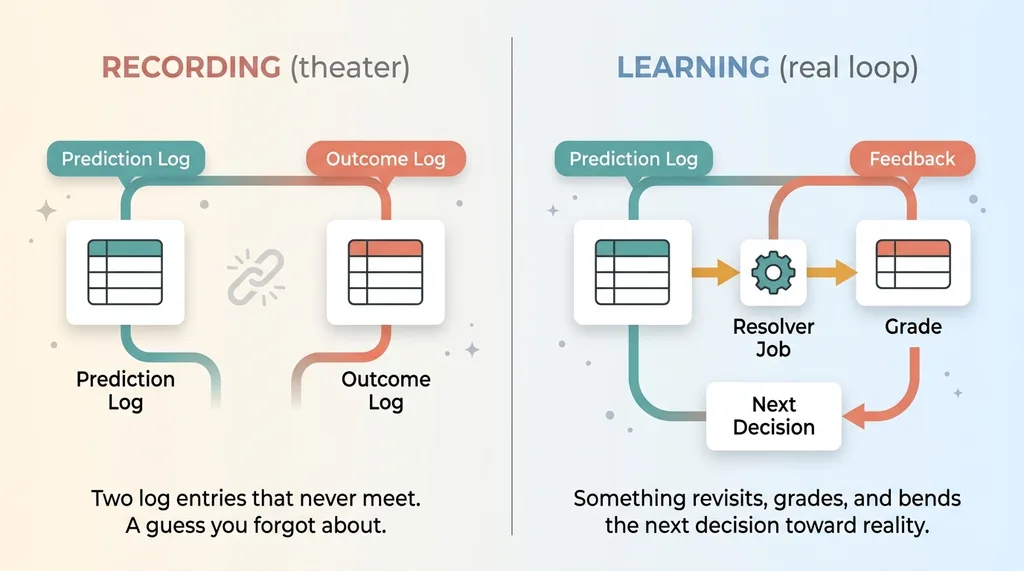
So let me press on it. What does "learns over time" actually mean in practice? For most systems I've seen, it means they record a prediction at one point, and they record an outcome at another point. That's it. Two log entries sitting in separate tables. Nothing ever picks them up, compares them, and changes behavior as a result.
Recording is not learning. Self-improving AI agents are supposed to close that gap, but the vast majority of what gets sold under that label never does.
Here's a confession to start with. My DTC fashion brand runs an ad-optimization agent. It predicted what a budget shift would do, executed the change, and logged the prediction. Then nothing checked whether the prediction was right. The agent ran like that for months. It looked sophisticated. It was theater.
That stung when I realized it, because I built the thing. I'm the guy who tells clients their AI needs accountability, and my own system was confidently making decisions with zero feedback on whether any of them worked.
So here's my thesis, and the whole article rests on it. A learning loop only exists if something revisits past decisions, derives the real outcome from real data, grades it, and bends the next decision toward reality.
Everything short of that is a dashboard pretending to be intelligence. A prediction with no reconciliation is a guess you forgot about. Closing the learning loop means building the unglamorous machinery that turns a guess into a track record, and a track record into a better next guess.
Most teams never build that machinery. They build the part that feels smart and skip the part that makes it true.
How I Found Out My Optimizer Never Actually Learned
The AI system that manages our Meta ads is one of the more complex things I've shipped. It scores decisions, logs predicted outcomes, and executes budget and creative changes on its own. From the outside it looked like a well-behaved autonomous agent.
Two things were quietly broken. Both were embarrassing once I saw them.
The predictor was a hardcoded constant
The "predictor" that estimated the impact of each change was not intelligent at all. It was a hardcoded constant dressed up to look like analysis. No matter what I fed it (a small budget bump, a big reallocation, a creative swap) it returned roughly the same expected lift.
So the agent would say "this change should improve return on spend by about this much," and that number was essentially fixed. It wasn't reasoning about the specific decision. It was reading a value off a shelf and presenting it as a forecast. The output had the shape of intelligence with none of the substance.
Predicted vs actual was never reconciled
The second problem was worse. The predicted outcome and the actual outcome lived in different places, and nothing ever joined them.
The agent logged what it expected. Performance data accumulated separately. No job ever woke up, matched a past decision to its real result, and asked the only question that matters: did that work?
The system could run for weeks, make dozens of changes, and never once know if a single one helped. It was the same failure family I wrote about in AI doesn't fail by doing the wrong thing, it lies about doing the right thing. The agent wasn't malicious. It just had no mechanism to be held accountable, so it reported confidence it hadn't earned.
The tell was the dashboard. Beautiful charts of predicted lift, stacked decisions, projected gains. And behind every one of those predictions, zero verification. A prediction nobody checks is just an opinion with a timestamp.
That's when I stopped trusting the agent and started building the part I'd skipped.
What 'Closing the Learning Loop' Actually Requires
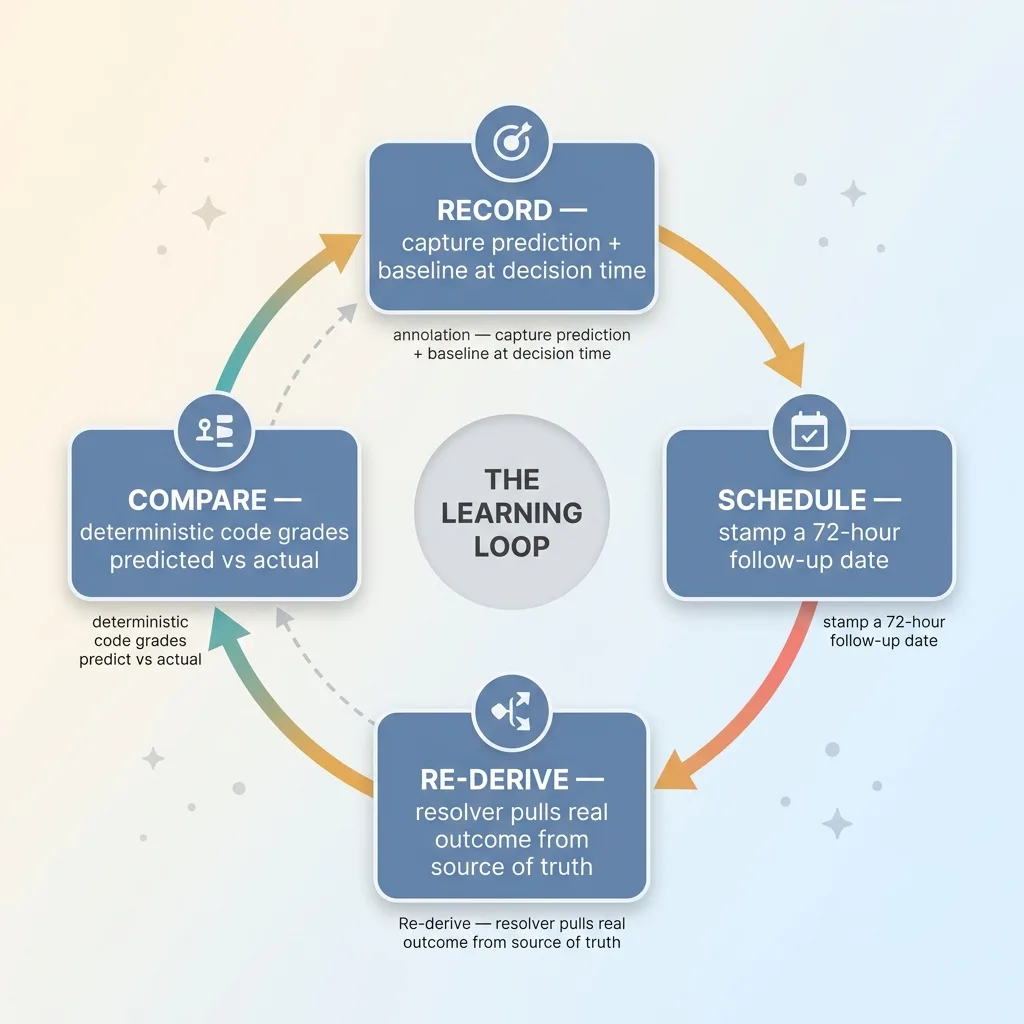
The fix isn't more AI. It's a loop with four parts, and you can explain all four to a CEO in two minutes. No machine learning degree required.
 The Four-Part Learning Loop (Record, Schedule, Re-derive, Compare)
The Four-Part Learning Loop (Record, Schedule, Re-derive, Compare)
Record the prediction at decision time
At the exact moment the agent executes a decision, capture two things: the prediction (what the agent expects to happen) and the baseline (where the metric stands right now). You need both, because "improved by X" is meaningless without knowing where you started.
This has to happen at decision time, not after. Reconstructing a baseline later is how you fool yourself.
Stamp a follow-up due date
Every gradable action gets a follow-up date stamped on it. In my case, 72 hours later.
That window matters. Too short and you're grading noise before real signal accumulates. Too long and the lesson arrives after the next ten decisions are already made. Seventy-two hours was long enough for meaningful volume to build and short enough to still be actionable. Different decisions need different windows, which I'll come back to.
Re-derive the real outcome later
A resolver job wakes up on a schedule, finds every action whose follow-up date has passed, and re-derives the observed metrics from real performance data.
Read that again. From real performance data. Not from the agent's memory of what it thought would happen. The agent doesn't get to grade its own homework from recollection. The resolver pulls fresh numbers from the source of truth and computes what actually occurred.
Then it compares predicted to actual. This is the step everyone skips, and it's the only step that turns logging into learning.
The grading math here is deterministic code, not a second LLM guessing. This is exactly the principle I covered in let the model judge and let the code compute. The model can decide what to do. The code computes whether it worked. You never want a language model improvising arithmetic on whether the last decision paid off.
Four parts. Record, schedule, re-derive, compare. The difference between tracking whether AI work actually pays off and just keeping a diary is whether step four exists.
Grading a Decision: Confirmed, Reverted, or Inconclusive
Once the resolver re-derives the real outcome, it assigns one of three grades. Three, not two. The third one is where the value hides.
 Three Grades: Confirmed, Reverted, Inconclusive
Three Grades: Confirmed, Reverted, Inconclusive
Confirmed. The real outcome moved in the predicted direction by a meaningful margin. The agent said return on spend would improve, and it improved enough to be sure it wasn't chance. This decision earned its keep.
Reverted. The change hurt, or the metric moved the wrong way. Cost per acquisition climbed when the agent expected it to fall. Conversion rate dropped after a creative swap. These get an alert, immediately, because a revert means money is leaking right now. The system has to tell me when it was wrong. Silence is not success.
Inconclusive. Not enough volume to call it, or the signal was indistinguishable from noise. The change happened, but the data can't support a verdict either way.
Why three buckets instead of a clean right-or-wrong? Because a binary grade throws away the most honest category. If you force every decision into "worked" or "didn't," you end up labeling random noise as a result, and then you train your agent on garbage. An agent that learns from noise gets worse, not better, and does it confidently.
Inconclusive is not a failure of the system. It's the system being honest about what the data can and can't tell you. In a low-traffic account, inconclusive will be common, and that's correct behavior, not a bug.
The alert on reverts is the piece I'd never ship without now. An autonomous agent that can lose money quietly is more dangerous than no agent at all. The moment a decision grades out as reverted, I want to know, so I can pull the change before it compounds.
Feeding the Track Record Back Into the Next Decision
Here's the payoff. Grading decisions makes an agent self-reporting. Feeding those grades back into the next decision makes it self-improving. That distinction is the whole game.
 Calibrated Prior Feedback, bending the next prediction toward reality
Calibrated Prior Feedback, bending the next prediction toward reality
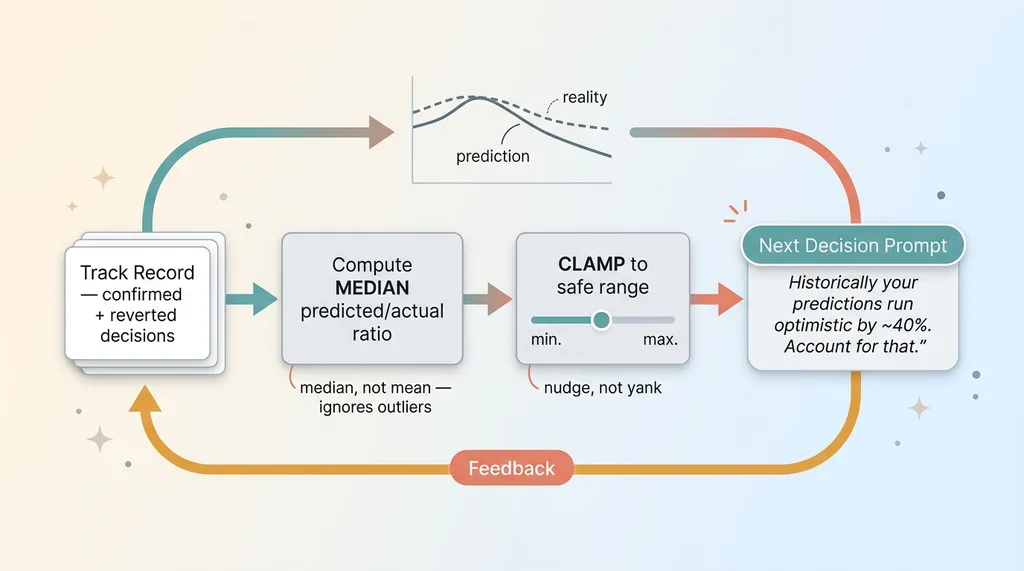
Once you've accumulated a track record of confirmed and reverted decisions, you compute the ratio between what the agent predicted and what actually happened. Over many decisions, that ratio tells you the agent's bias.
The median predicted/actual ratio
You use the median ratio, not the mean. This matters. One viral post or one broken tracking day can produce an outlier so extreme it drags a mean into nonsense. The median shrugs that off. It tells you the typical relationship between prediction and reality, which is exactly what you want a prior built on.
If the agent consistently overpredicts lift by 40%, the median ratio captures that. The next prediction then gets bent toward reality by that factor.
Clamping to a safe range
You also clamp the adjustment to a safe range. Without a clamp, one strange week could whipsaw the agent into wild overcorrection, and now you've replaced overconfidence with overcaution. The clamp keeps the calibration honest and stable. It can nudge the agent, it can't yank it.
That calibrated prior gets injected straight into the agent's next prompt. In plain terms, the agent's instructions now include something like: "Historically your predictions run optimistic by roughly this much. Account for that before you commit."
The agent's own track record changes how it thinks about the next call. It stops trusting its raw instinct and starts correcting for its documented bias. That's the loop closing. Not a marketing phrase. An actual mechanism where past performance reshapes future behavior, automatically, every cycle.
Why Most Vendor 'Learning' Claims Don't Survive This Test
Now turn this around and point it at any vendor or in-house system claiming it learns. Four questions. Make them answer all four.
 The Four Questions That Expose Fake Learning
The Four Questions That Expose Fake Learning
- Where do you store the prediction at decision time? Not the outcome. The prediction, captured the moment the decision executes, with the baseline.
- What re-derives the actual outcome, and from what data source? There must be a named job pulling from a real source of truth, not the agent's own memory.
- What grades the gap, and how often? Deterministic code, on a schedule, producing confirmed, reverted, or inconclusive.
- Where does that track record show up in the next decision? If the answer is "it doesn't, but we review it quarterly," it doesn't learn. It logs.
If they can't answer all four cleanly, you're looking at a system that records outcomes and calls it intelligence.
Now let me be honest about the limits, because I won't sell you a clean story. A 72-hour window doesn't fit every decision. Some need a full week to show real signal. Some need a day. You set the window per decision type, and getting that wrong quietly poisons the grades.
The calibration only helps where you have enough volume. In low-traffic accounts, inconclusive grades pile up and the track record builds slowly. That's reality, not a defect, but it means the loop improves a busy account faster than a quiet one.
This is the same discipline I wrote about in tracking whether AI work actually pays off. Proving value requires the boring accountability layer, not a flashier model. The vendors who can answer the four questions are rare. They're also the only ones worth paying.
What This Looks Like When It's Built Into Your Stack
Most companies don't need a smarter AI. They need the accountability layer underneath the one they've got.
The resolver cron that wakes up and grades old decisions. The follow-up dates stamped on every action. The deterministic grading that won't pretend noise is a win. The calibrated prior that bends the next decision toward what actually happened. None of it looks impressive in a demo. All of it is the difference between an agent that performs intelligence and one that earns it.
I build this loop into every autonomous system I ship for clients now, and not as a feature you can add later. As the design. Nothing runs in production without something that grades it after the fact. An agent that can't be wrong out loud is an agent I won't deploy.
If you've got an AI system making decisions and nobody can tell you whether those decisions are working, that's the gap worth closing before you build anything new on top of it. The flashy layer can wait. The accountability layer can't.
When you're ready, let's talk about what a real learning loop looks like in your stack.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call