Ad Creative Testing Automation Without Betting Budget
How I built ad creative testing automation that spins every cleared concept into a capped cold-start cell, so my ad bot finds new winners without risking real money.
By Mike Hodgen
The Problem With an Ad Bot That Only Scales Winners
Here is the embarrassing number I had to stare at: 27 approved creative concepts sitting paused, exactly 1 ad live, and 0 autonomous ads ever shipped.
 Exploration vs Exploitation Tradeoff
Exploration vs Exploitation Tradeoff
That was the state of the ad system I built for my DTC fashion brand. And it was not because the system was bad. It was because the system was good at the wrong thing.
My ad bot was excellent at exploitation. Feed it a creative that converted, and it would pour more budget into that creative with cold precision. Spend follows performance. That part worked beautifully.
What it could not do was test anything new cheaply. There was no mechanism for ad creative testing automation built into it. So when the creative engine produced 27 fresh concepts, they had nowhere to go. They piled up in "approved" status like unread email.
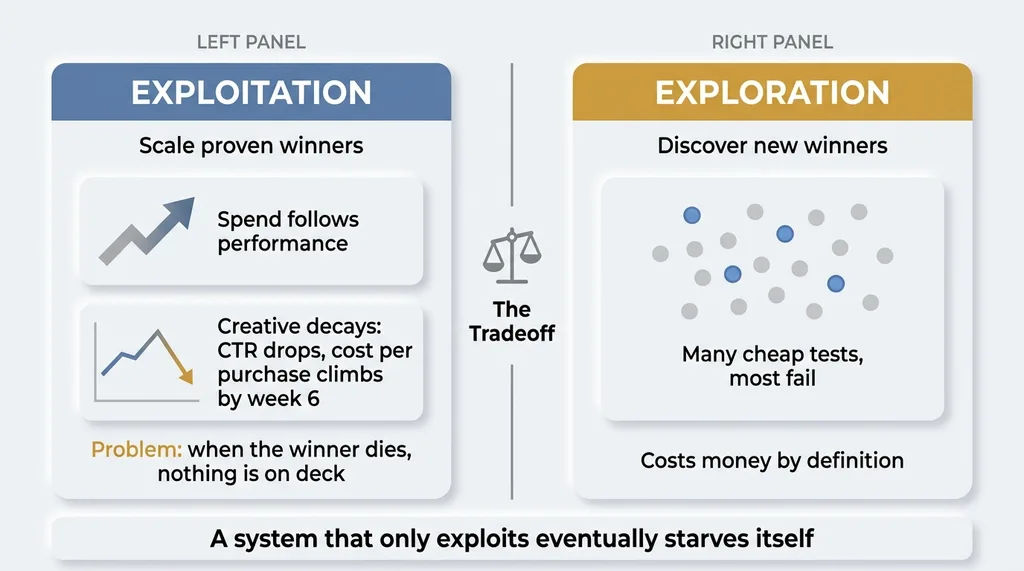
This is the classic exploration versus exploitation tradeoff, and most ad automation lands hard on one side. Exploitation milks proven winners. Exploration hunts for new ones. A system that only does the first eventually starves itself.
Here is why. Every winning ad decays. The audience sees it enough times, fatigue sets in, click-through drops, cost per purchase climbs. The thing that printed money in week one is a tax by week six.
An optimizer that only scales winners has no answer for this. When the current winner dies, there is nothing in the on-deck circle. No tested challenger waiting to take over. Just a bot frantically scaling a corpse.
So I had built a machine that was perfectly tuned to ride a single horse into the ground. It could not go find the next horse. The whole pipeline was stalled because the loud, easy half of the problem was solved and the quiet, hard half had been skipped entirely.
That hard half is what this article is about.
Why Cold-Start Testing Is the Part Everyone Skips
Scaling is easy to automate because the signal is loud. A creative converts, you spend more on it. The data screams what to do.
Discovery is the opposite. New creative has zero history. The ad platform has never shown it, so it has no idea who to target or whether it works. This is cold start advertising, and it is genuinely expensive to get through.
During that cold-start learning window, you are spending real money on something completely unproven. The platform is feeling around in the dark, burning budget to gather signal. Most of that early spend teaches you the ad is mediocre.
So teams do one of two things. Either they never test new creative at all (the pipeline stalls, like mine did), or they dump a real budget into a test, watch it flop, and lose a meaningful chunk of money.
Here is the honest tension nobody wants to say out loud: you cannot find new winners without spending on losers first. There is no clean version of discovery. Exploration costs money by definition, and most of what you explore will not pan out.
The trick is not avoiding losses. The trick is making each individual bet so small that the loss does not matter. If a failed test costs me a coffee, I can run a hundred of them and not flinch.
But you cannot just "turn on a $2 ad" and call it testing. The platform's own optimizer needs a minimum amount of spend to exit its learning phase. Starve it and it never gets enough signal to tell you anything real. You get noise, not an answer.
So micro-tests have to be structured deliberately. Small enough that any single one is disposable, large enough that the platform can actually learn from it. That balance is the entire game, and it is exactly the part most ad automation skips.
The Test-Cell Budget Guardrail: A $7/Day Cap Primitive
The first thing I built was not the clever discovery logic. It was the guardrail that makes discovery safe.
I call it a test-cell budget guardrail, and its default is a hard cap of $7 a day. That is a real number from my own brand, not a textbook figure.
Why a hard cap, not a percentage
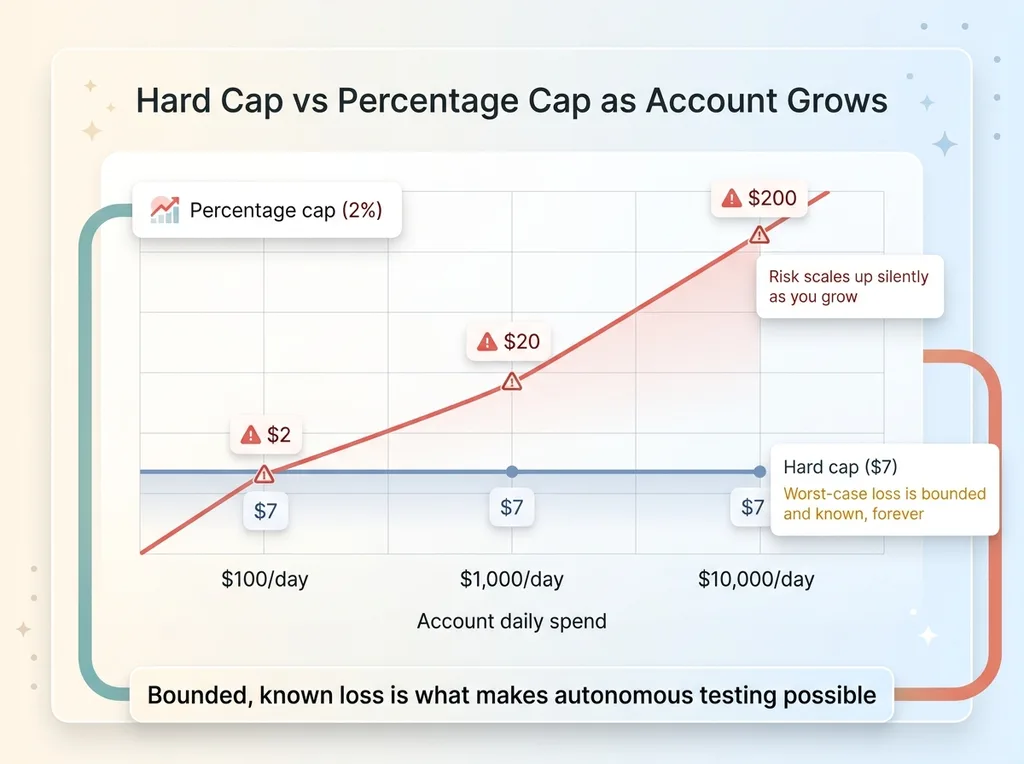
The obvious move is to cap test spend at a percentage of the account. Two percent of budget, something like that. I deliberately did not do this.
 The $7/Day Hard Cap vs Percentage Cap
The $7/Day Hard Cap vs Percentage Cap
A percentage scales your risk up as the account grows. Spend more overall, and suddenly each "small" test is risking more dollars. The whole point of exploration is that a single failed test can never hurt you, and a percentage cap quietly breaks that promise the moment the account scales.
A hard dollar cap does not. Seven dollars is seven dollars whether the account is spending $100 a day or $10,000 a day. The worst-case daily loss on any single test is bounded and known, forever.
That bounded, known loss is the thing that makes autonomous testing psychologically and financially possible. I do not have to wonder how bad a runaway test could get. I already know. It is $7.
Making the cap a reusable building block
I did not bury this as a setting inside one campaign. I built it as a primitive, a reusable building block the whole system can call.
Every test cell the system spins up inherits the same cap by default. Each cell is isolated, capped, and disposable. One flops, you lose your bounded amount and move on. Nothing leaks into anything else.
This is the foundation. You cannot let a machine create ads autonomously unless you have already made the cost of any single mistake trivially small. The guardrail came first because everything dangerous gets built on top of it.
Reviving the Creative Pipeline So Cleared Concepts Go Live
The second fix was less clever and more important: wiring two working systems together.
 The Stalled Pipeline and the Missing Bridge
The Stalled Pipeline and the Missing Bridge
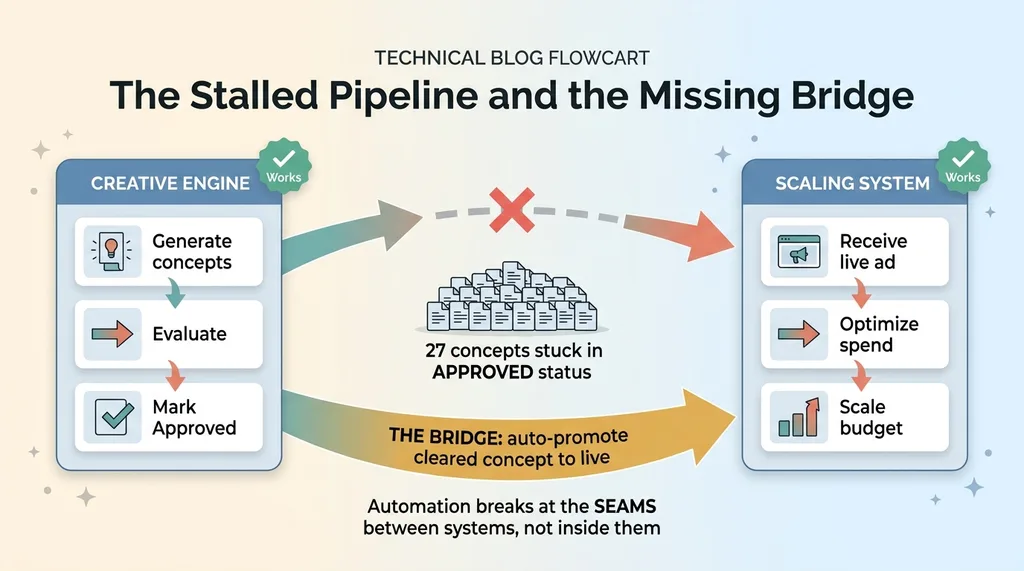
The creative engine that produced and cleared concepts was completely disconnected from anything that actually launched ads. That is why 27 concepts rotted in "approved" status. They got created, they got cleared, and then they hit a wall.
The concepts themselves came out of the specialist agents that manage our Meta ads. That side worked. It generated creative, evaluated it, marked the good ones as approved. Clean handoff right up until the handoff to nothing.
The scaling side worked too. Give it a live ad and it would optimize spend competently.
What did not exist was the bridge between them. Cleared concepts had no automatic path to going live. A human had to manually take an approved concept and launch it, and humans are busy, so nobody did. The pipeline silted up.
So I rebuilt the handoff. Now a cleared concept auto-promotes to live instead of sitting in a paused graveyard. The bridge exists.
This is the lesson I keep relearning across every system I build: automation breaks at the seams between systems, not inside them. The creative engine was fine. The scaler was fine. The gap between them was where everything died.
The bridge work is unglamorous. There is no impressive model, no clever algorithm, just plumbing that moves an object from one system's "done" state to another system's "input." But it was the single highest-leverage thing I could fix, because it took a stalled pipeline of 27 wasted concepts and turned it back into a flow.
Nobody brags about plumbing. The plumbing is usually what is actually broken.
The Exploration Engine: Every Cleared Creative Gets Its Own Cold-Start Cell
Here is the core of it. When a creative clears, the system automatically creates it as its own capped test cell inside a single persistent exploration campaign.
That sentence has two design decisions buried in it, and both matter.
One persistent exploration campaign
Every cell lives inside one campaign that never gets torn down. This is deliberate.
If I spun up a fresh campaign for every test, the platform would cold-start from scratch every single time. Zero accumulated learning, maximum wasted spend on the discovery phase, over and over.
By keeping one persistent exploration campaign, the platform accumulates learning at the campaign level. Each new cell starts a little less blind than it would have, because the campaign already knows something about who responds. It softens the cold-start tax across every test instead of paying it fresh each time.
Purchase-optimized, not click-optimized
Every cell is optimized for purchases. Not clicks, not impressions, not engagement.
This is where a lot of testing systems quietly lie to themselves. Optimize for cheap clicks and you will find creative that gets cheap clicks. That is a vanity win. Cheap clicks that never buy anything are just an efficient way to waste money.
I only care whether a creative produces purchases. So that is what each cell optimizes for, even though it makes the cold-start window slower and more expensive. The honest signal costs more to gather. It is worth it because it is the only signal that means anything.
The structure that falls out of this: many small bounded cells running in parallel. Each one is a real chance to discover a winner. None of them can do meaningful damage, because each is capped at that disposable $7.
This is how you answer the buyer's natural doubt, which is "isn't autonomous ad creation just expensive guessing?" No. It is constant tiny experiments, each one bounded, each one optimized for the thing that actually matters. The system finds new winners by running dozens of cheap real tests, not by betting big on a hunch.
The exploration engine plugs into the broader architecture where I collapsed three ad systems into one engine. Discovery is one module in that engine. It does not replace the scaler. It feeds it.
Graduating Winners and Killing Losers Automatically
A discovery system is useless if a human has to babysit every cell. If I have to manually check 30 test cells and decide which survive, I have just invented a new full-time job for myself.
 The Full Exploration-to-Exploitation Engine Loop
The Full Exploration-to-Exploitation Engine Loop
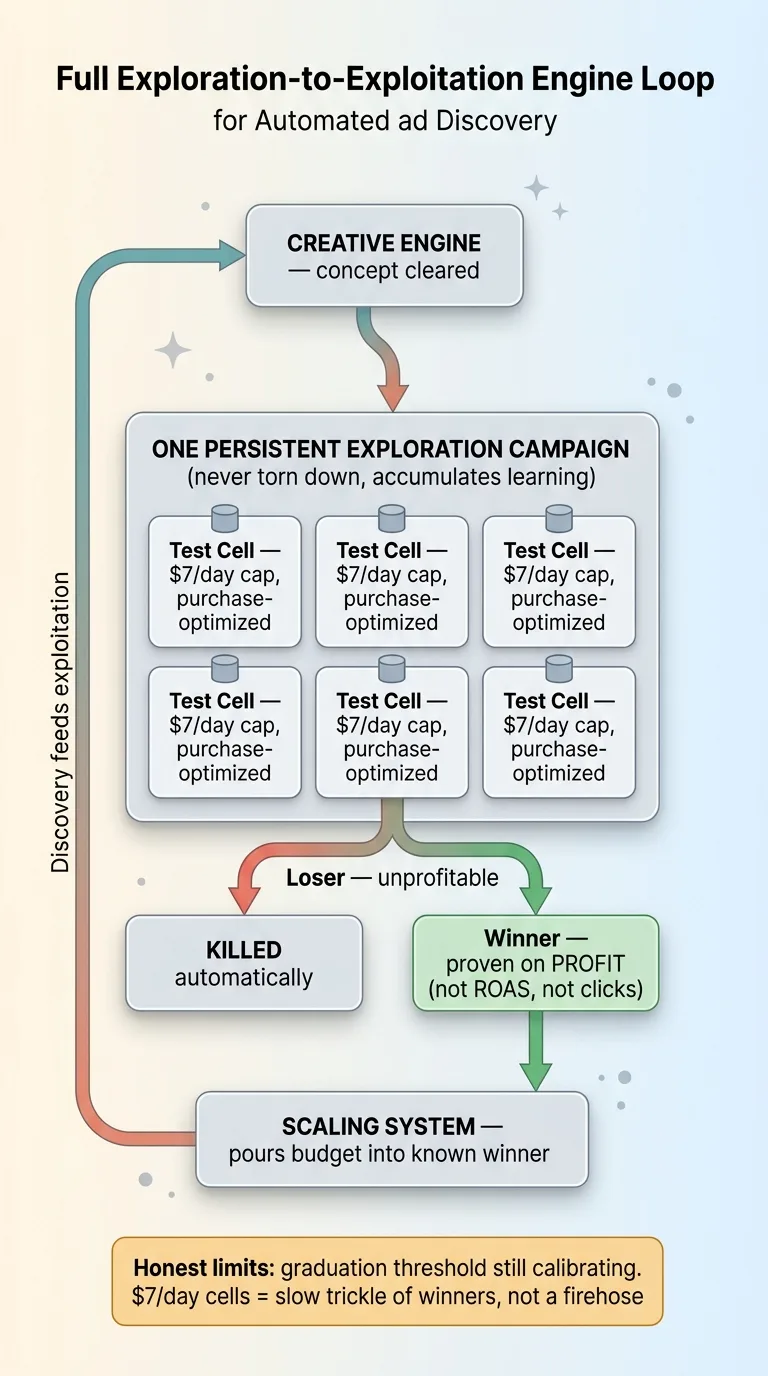
So the loop closes automatically. A test cell that proves itself gets promoted out of exploration and into the main scaling system. One that does not earns its way out and gets killed.
The standard for "proven" is the part that matters most. It is profit, not surface metrics.
A cell can have a gorgeous click-through rate and still lose money. It can have a ROAS number that looks great on a dashboard and still be unprofitable once you account for real costs. I do not graduate on any of that. I graduate on whether the creative actually makes money, which I optimize on profit, not ROAS for across the whole system.
This is exploration feeding exploitation, the way it should work. Discovery hunts, finds a proven winner, and hands it to the scaler. The scaler does what it is genuinely good at: pouring budget into a known winner with precision. Each half does its job.
Now the honest part. This is not perfectly tuned yet.
The graduation threshold is still being calibrated. Set the bar too high and good creative gets killed before it proves itself. Too low and mediocre creative graduates into the scaler and wastes real budget. Finding that line takes live data and patience.
And a $7-a-day cell takes time to reach statistical confidence. At that spend level, you are not getting an answer in a day. You are getting it over a week or more. So this is a slow drip of new winners, not a firehose.
I would rather tell you that than oversell it. A steady trickle of profitable, tested creative feeding the scaler beats a stalled pipeline of 27 paused concepts every single day. But it is a trickle, by design.
Shipped Paused: Why It Never Auto-Spends Until I Arm It
The entire exploration engine shipped paused. It is behind an off-by-default flag. It cannot spend a single dollar until I explicitly arm it.
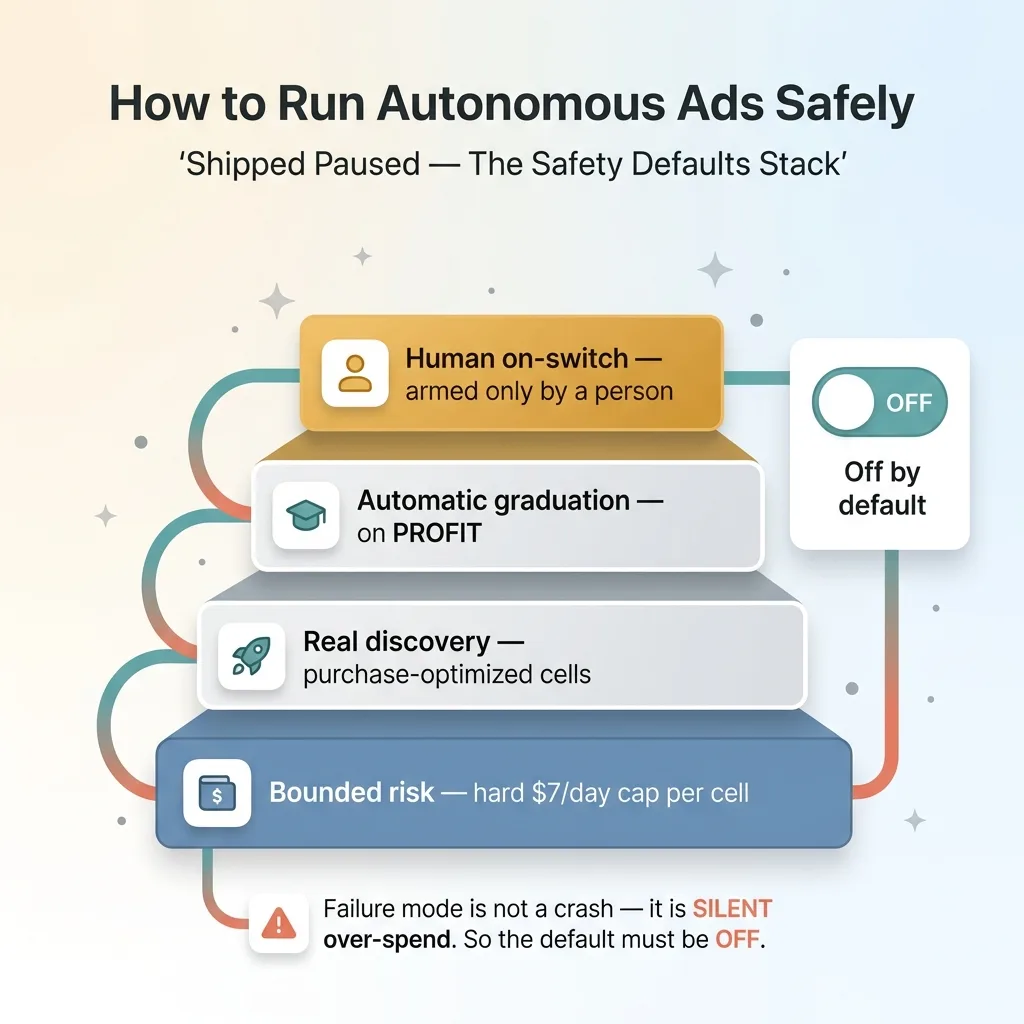 Shipped Paused, The Safety Defaults Stack
Shipped Paused, The Safety Defaults Stack
That is not caution for caution's sake. It is the only responsible default for any system that moves real money on its own.
Think about the failure mode of a discovery engine. It is not a dramatic crash. It is silent over-spend. The system quietly creates more cells than expected, or a cap gets misconfigured, or graduation logic promotes garbage into the scaler. You do not notice until the spend report comes in.
When the failure mode is silent and financial, the default has to be safe. Off. Armed only by a human who is paying attention. This is the same discipline behind the off-by-default flags and kill-switches I build into every system that touches money or customers.
So here is the whole picture. Bounded risk through a hard $7 cap. Real discovery through purchase-optimized cells. Automatic graduation on profit. And a human holding the on-switch.
That combination is how an automated ad system finds new winners instead of milking old ones, safely. You get exploration without betting the budget, and you stay in control of the part that matters.
If your ad spend is either stagnant (the bot only scales old winners and you can feel the pipeline drying up) or scary (you are afraid to let automation anywhere near the budget), this exploration-with-guardrails pattern is exactly the kind of thing I build. I would genuinely like to look at your ad stack and tell you where the seams are broken.
Come talk to me about your ad stack.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call