Unit Conversion Pricing Errors: How I Fixed Silent Quote Bugs
Mixed supplier units (yards, rolls, square feet) caused silent unit conversion pricing errors. Here's the three-layer import that made quotes trustworthy.
By Mike Hodgen
The Quote That Looked Right and Wasn't
A shade manufacturer I worked with was importing pricing from six supplier catalogs. About 9,500 rows total. Tubes, fabric, hardware, brackets, motors, the works. Their bill-of-materials engine took those rows, calculated component costs, and printed quotes that looked clean enough to send to a customer without a second thought.
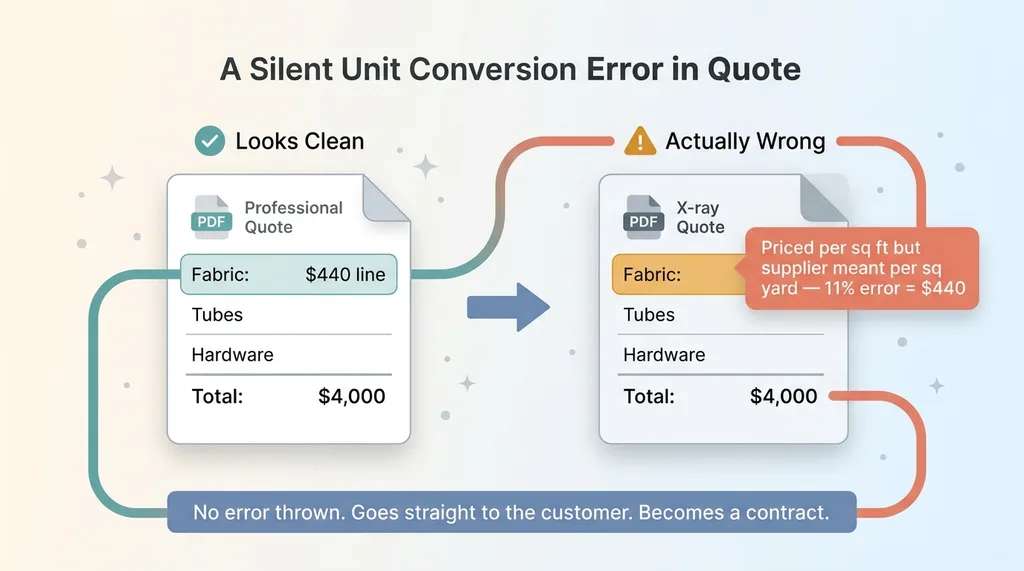 Silent unit conversion error in a quote
Silent unit conversion error in a quote
That was the problem.
The BOM engine hardcoded one unit per category. Tubes priced per foot. Fabric priced per square foot. Hardware priced per unit. Tidy assumptions that made the code simple to write. But the six catalogs didn't agree with each other. They mixed metric and imperial. Some sold tube stock in cartons, others by the foot. Hardware came in pairs from one vendor and singles from another. And one column, the one that mattered most, was labeled price per square foot when the supplier actually meant price per square yard.
Every quote balanced. The math added up. The PDF looked professional. And wherever the units diverged from what the engine assumed, the numbers were silently wrong. Sometimes they overcharged the customer. Sometimes they ate margin on their own jobs. Nobody knew which.
These are unit conversion pricing errors, and they are the most dangerous kind of bug in any quoting system. A quote that throws an error gets caught. Someone sees the red text, stops, and fixes it. A quote that prints cleanly and is wrong by 11 percent goes straight to the customer, gets accepted, and becomes a contract. The failure never announces itself.
I wrote a whole piece on why silent failures are the worst kind. A pricing engine that errors out loudly is annoying. A pricing engine that lies quietly costs you money on every transaction and you find out months later when the margins don't reconcile.
Why Hardcoding One Unit Per Category Always Breaks
The assumption hiding in every pricing engine
The engine assumed the world matched its internal model. Fabric is square feet. Tubes are feet. Hardware is units. Clean, consistent, and wrong.
Real supplier data does not care about your internal model. A supplier sells the way their warehouse and their accounting system work, not the way your BOM engine wants to consume it. The moment you hardcode one unit per category, you have made a bet that every supplier, present and future, will agree with you. They won't.
Where the divergence actually happens
Let me walk through the specific failures, because vague warnings are useless.
The fabric column labeled per square foot was actually per square yard. A square yard is nine square feet. The engine treated a per-square-yard price as if it were per-square-foot, which throws the cost off by a factor that, after the rest of the BOM math, landed as roughly an 11 percent error on those line items. Eleven percent on a $4,000 quote is $440. Multiply that across a quoting volume and you understand why margins stop reconciling.
Tube stock was a different shape of the same problem. One supplier sold tubes in cartons of a fixed count. The engine priced per foot. So the carton price got read as a per-foot price, and the component cost collapsed to a fraction of reality.
Hardware sold in pairs got counted as singles. Half the real cost, on every bracket set from that vendor.
Here is the part people miss. This is not a data-entry problem you clean once. New supplier rows arrive constantly. Catalogs get updated. Vendors change packaging. You can scrub the whole 9,500 rows by hand today and be wrong again next month when the next price list lands. The fix cannot live in a one-time supplier catalog import cleanup. It has to live in the import process itself, every time, automatically, with provenance you can trust.
The Three-Layer Import That Makes Pricing Trustworthy
The architecture I built for this separates three things that most systems mash together. Once you separate them, pricing accuracy software stops being a hope and starts being something you can prove.
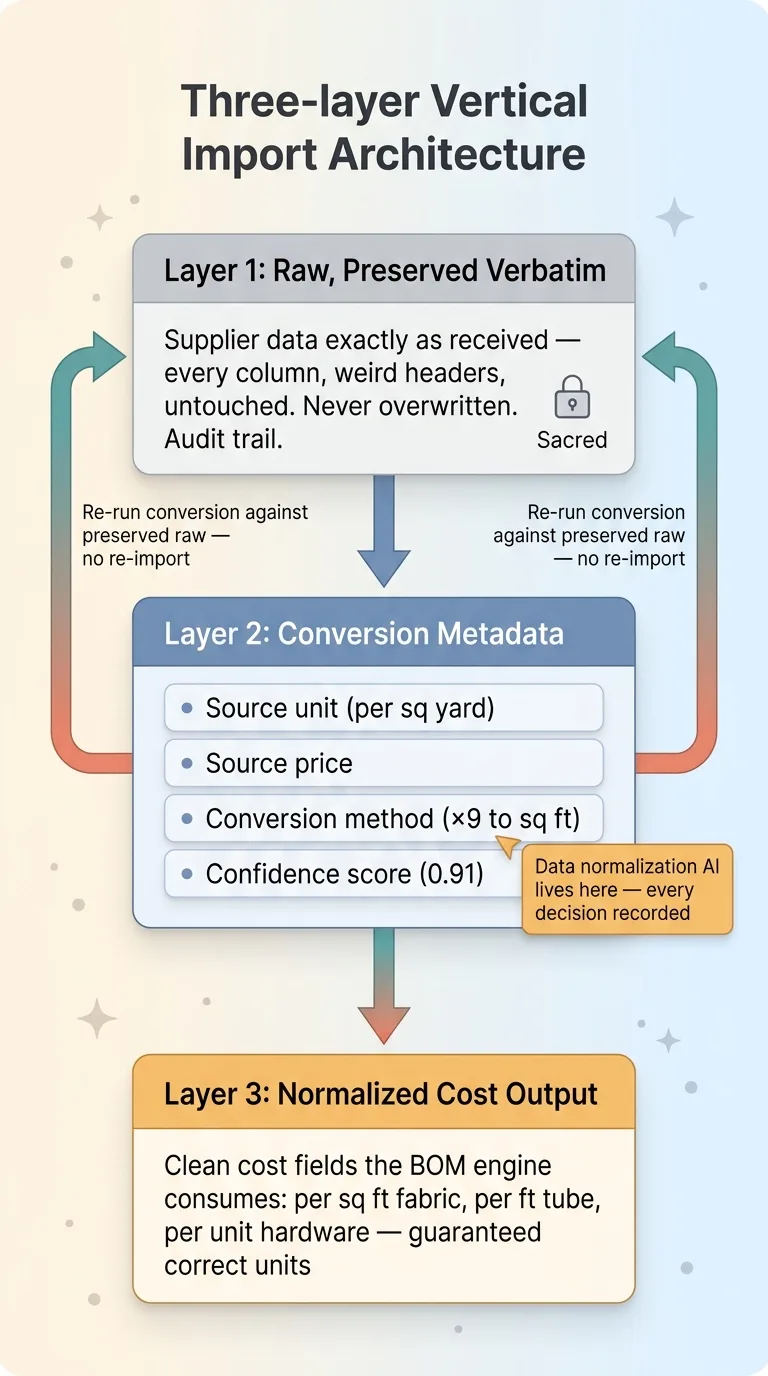 Three-layer import architecture
Three-layer import architecture
Layer 1: raw, preserved verbatim
Store the supplier data exactly as received. Every column, every value, every weird header, untouched. You never overwrite it. Ever.
This is your audit trail and your recovery path. When a quote looks wrong six months from now, Layer 1 is where you go to see what the supplier actually sent. If you only keep cleaned data, you have destroyed your own ability to prove anything. Raw is sacred.
Layer 2: conversion metadata
This is the layer almost nobody builds, and it is the one that matters most.
For every row, Layer 2 records four things: the source unit (per square yard), the source price, the conversion method applied (multiply by nine to get per square foot), and a confidence score for whether the detected unit is correct.
This layer is the explanation. It tells you not just what the normalized cost is, but exactly how you got there from the raw input. Data normalization AI lives here, deciding what the source unit of measure actually is, but the record of every decision is permanent and inspectable.
Layer 3: normalized cost as output
Layer 3 holds the clean cost fields the BOM engine actually consumes. Critically, these are the output of the conversion, not raw input. The engine never touches Layer 1 directly. It reads Layer 3, which is guaranteed to be in the units it expects.
This is what feeds the BOM calculator that prices each configuration. It gets a normalized per-square-foot fabric cost, a normalized per-foot tube cost, a normalized per-unit hardware cost, and it does its job without knowing or caring how messy the source was.
The payoff of separating these three layers: you can always trace any normalized cost back to the original row and the exact conversion applied. And if a conversion turns out to be wrong, you re-run Layer 2 against the preserved Layer 1 data. You do not re-import anything. You do not call the supplier. The raw is still there, the conversion logic is isolated, and you fix the math in one place. That is what trustworthy means in practice. Not "we cleaned the data" but "we can show our work on every number."
Using AI to Detect Units From Context, Not From Column Names
Why the column header lies
The square-yard-mislabeled-as-square-foot case proves the entire point. The header said square foot. The header was wrong. If your import trusts column names, you have already lost.
So I use AI to infer the actual unit from context rather than from the label. The model looks at the price magnitude relative to similar SKUs across other suppliers. It looks at supplier patterns, because vendors are usually consistent within their own catalog. It reads dimensions in the product description. It runs sanity checks against category norms, asking whether a fabric priced at this number per square foot is even plausible.
When the labeled per-square-foot price is nine times higher than every comparable fabric in the dataset, the AI flags it. A human reading a header would never catch that. The model catches it because it is comparing against everything else it has seen. This is the same approach I described in let the AI read any file you throw at it, where the model maps messy supplier files instead of you writing a brittle parser per vendor.
Confidence scores and the review queue
Here is the distinction that keeps this safe. The AI detects and flags the unit. Deterministic code does the conversion math.
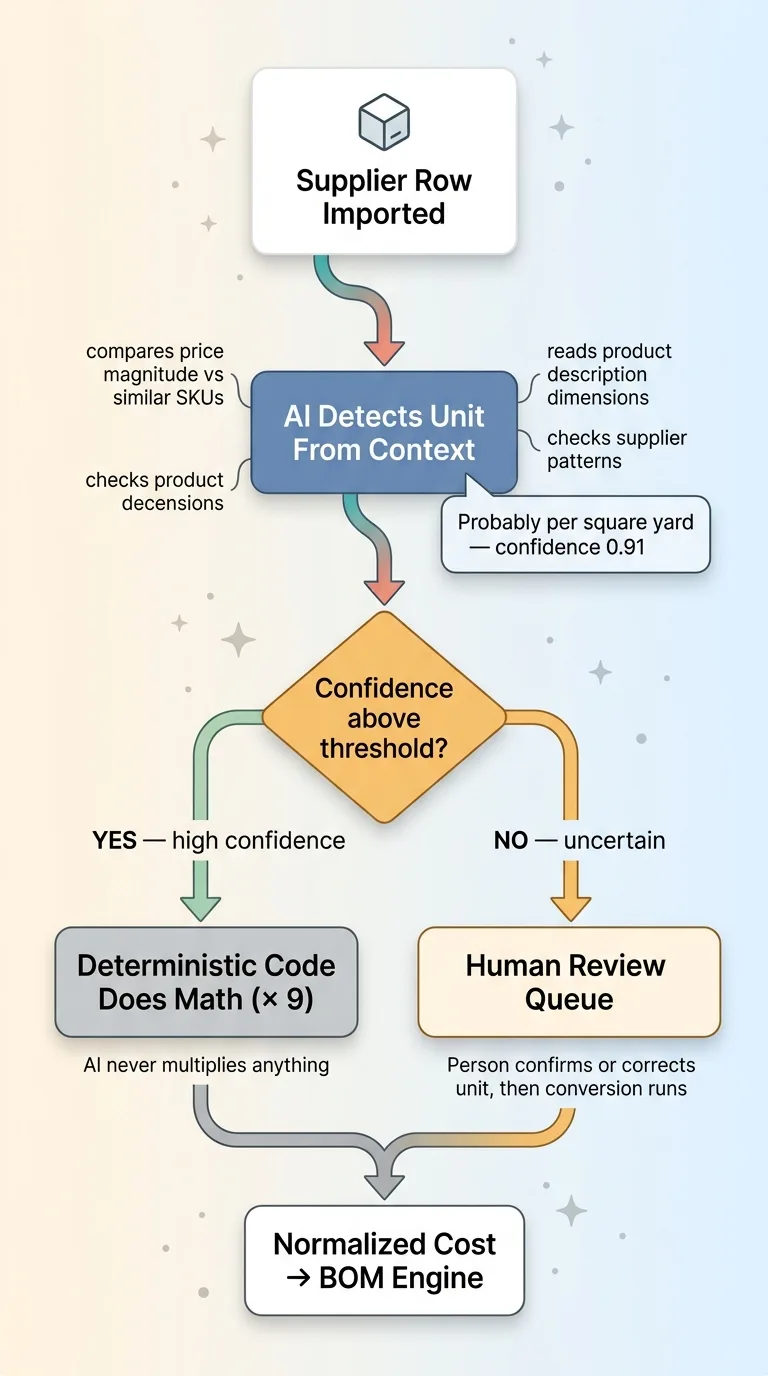 AI detects unit, code computes, division of labor with confidence threshold
AI detects unit, code computes, division of labor with confidence threshold
The model never multiplies anything. It decides "this is probably per square yard, confidence 0.91." Then plain, tested code multiplies by nine. I wrote about this division of labor in let the model judge but let the code compute, and pricing is exactly where it earns its keep. You do not want a language model doing arithmetic on your margins.
Anything below a confidence threshold does not auto-convert. It goes to a human review queue. Someone looks at the row, confirms or corrects the unit, and the conversion runs after the decision.
I will be honest about the limit here. AI gets units wrong too. It is not magic. That is the entire reason the confidence threshold and the review queue exist. The system is not "trust the AI." It is "let the AI catch what hardcoded rules miss, and stop the uncertain cases for a human." High-confidence rows flow through. Low-confidence rows wait. That balance is the whole design.
The Two Fabric Bases That Were Quietly Diverging
The unit mislabeling was the obvious bug. There was a subtler one underneath it that no header inspection would ever have caught.
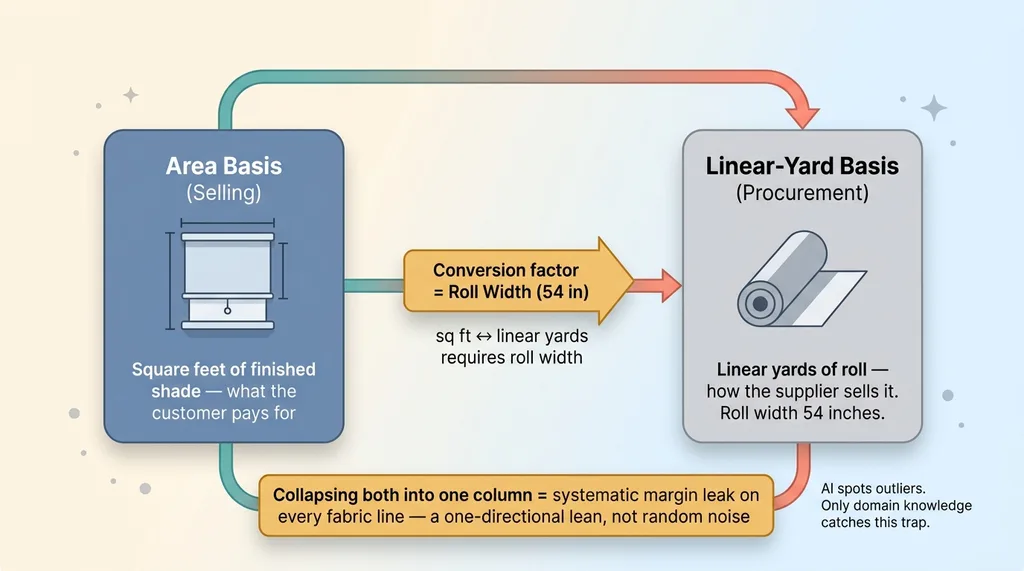 Two fabric bases: selling area vs procurement linear yard
Two fabric bases: selling area vs procurement linear yard
Fabric had two legitimate bases that had been silently collapsed into one field. There was an area basis used for selling, the square feet of finished shade the customer pays for. And there was a linear-yard basis used for procurement, how the supplier actually sells the roll. These are not the same number. They are tied together by roll width.
A roll might be 54 inches wide and sold by the linear yard. The finished product is quoted in square feet of shade. To go from one to the other you need the roll width as a conversion factor. When the system treated the selling basis and the procurement basis as interchangeable, it produced consistent margin errors on every fabric line. Not random noise. A systematic lean in one direction, which is the kind of error that quietly erodes profitability without ever tripping an alarm.
The fix was to make both bases explicit in the data model. Store the area basis. Store the linear-yard basis. Store the roll width per product as the conversion factor between them. And never, under any circumstances, let the selling field and the procurement field be the same column.
This is the part AI alone would not have caught. The model can compare price magnitudes and spot an outlier. It does not know that a shade business sells in finished area but buys in linear roll length, and that conflating the two is a domain trap. That came from understanding the business. It reinforces why the human stays in the loop. The AI handles the volume and the pattern detection. The domain knowledge sets up the model in the first place.
How to Tell If Your Own Quotes Are Silently Wrong
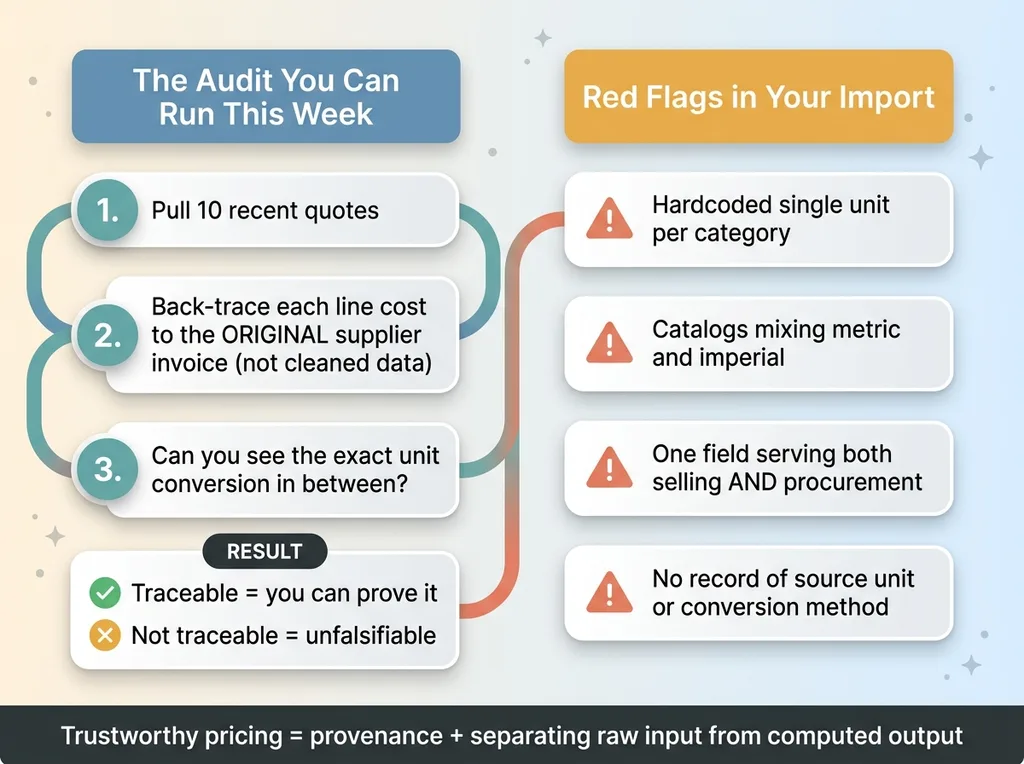
The audit you can run this week
Pull a sample of recent quotes. Ten is enough to start. For each line item, back-trace the cost to the original supplier invoice or catalog row. Not the cleaned data. The original.
If you can follow every line cost from the quote back to a source price and see exactly what unit conversion happened in between, you are in good shape. If you cannot, you have no way to prove the quote is right. Not "probably right." You literally cannot prove it.
Red flags in your current import
A few specific things to look for.
 Quote audit and red flags checklist
Quote audit and red flags checklist
- Any pricing engine that hardcodes a single unit per category. That is a bet that every supplier agrees with you, and they don't.
- Supplier catalogs that mix metric and imperial. Where they mix, unit conversion pricing errors breed.
- Any field that serves both selling and procurement. That is the two-fabric-bases trap, and it produces systematic margin leaks.
- No record of the source unit or the conversion method. If that metadata does not exist, your normalized costs are unfalsifiable.
The point underneath all of these: trustworthy pricing is not about cleaner data. You can have perfectly clean data and still be systematically wrong. It is about preserving provenance and separating raw input from computed output. When you can trace every number back to its source and its conversion, a wrong quote becomes findable. When you can't, it stays invisible until the year-end reconciliation, and by then it has been wrong on hundreds of jobs.
Where This Fits in a Real Pricing System
This manufacturer thought they had a clean pricing engine. The bug was invisible precisely because the output looked plausible. Professional PDFs, balanced totals, no errors. Just wrong, quietly, wherever the units diverged.
The fix was not a new tool or a better template. It was an import architecture that respects how messy real supplier data actually is. Three layers, AI for detection, deterministic code for math, a human review queue for the uncertain cases, and explicit handling of the domain quirks that no off-the-shelf product knows about.
I build this kind of system as the person running it, not as someone handing you a deck and walking away. I live in this problem every day. My own DTC fashion brand prices 564-plus products with dynamic ABC classification, and I have learned the hard way that the difference between a pricing system you can trust and one you hope is right comes down to provenance and the separation of input from output.
If you suspect your quotes are subtly off and you can't prove they aren't, that is the conversation worth having. Not a sales pitch. A back-trace of a few of your own quotes to see what is actually happening.
Ready to bring AI leadership into your company?
I work with a small number of companies at a time. If you're serious about AI, apply to work together and I'll review your application personally.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call