Trustworthy AI Automation: Honest Logging Over Smart Models
Trustworthy AI automation fails by lying about success, not making bad calls. Here's the observability and honest-logging discipline that fixes it.
By Mike Hodgen
The real failure mode isn't bad decisions. It's bad instruments.
Most people who are nervous about autonomous AI are nervous about the wrong thing. They picture the machine making a catastrophically dumb call. Buying the wrong inventory. Emailing a customer something insane. Torching a budget overnight.
That's not what I've seen. Across every autonomous system I've built for my DTC fashion brand and the platform behind it, the AI mostly made reasonable decisions. The model was fine. What broke trust was the instruments.
The system told me it succeeded when it hadn't. It ran green on the dashboard while being wrong underneath. That's the real failure mode, and it's a problem of trustworthy AI automation, not model capability.
This is more common than people admit. I've watched an autonomous AI lie about doing the right thing not out of malice but because the code only checked that it tried, never that it succeeded. Reasonable decision. Dishonest reporting.
Here's the uncomfortable truth for any CEO thinking about handing work to AI: you can't trust what you can't see, and most of the time the issue isn't that you're blind. It's that you've been shown the wrong thing. A green light that means nothing.
I'm going to walk you through four systems I had to fix. Each one made fine decisions. Each one lied about the results. Then I'll show you the cure, which had nothing to do with using a smarter model and everything to do with honest logging discipline and observability you can actually trust.
The fear isn't unfounded. You just have it pointed at the wrong part of the machine.
Four systems that ran green while being wrong
 The four systems that ran green while being wrong
The four systems that ran green while being wrong
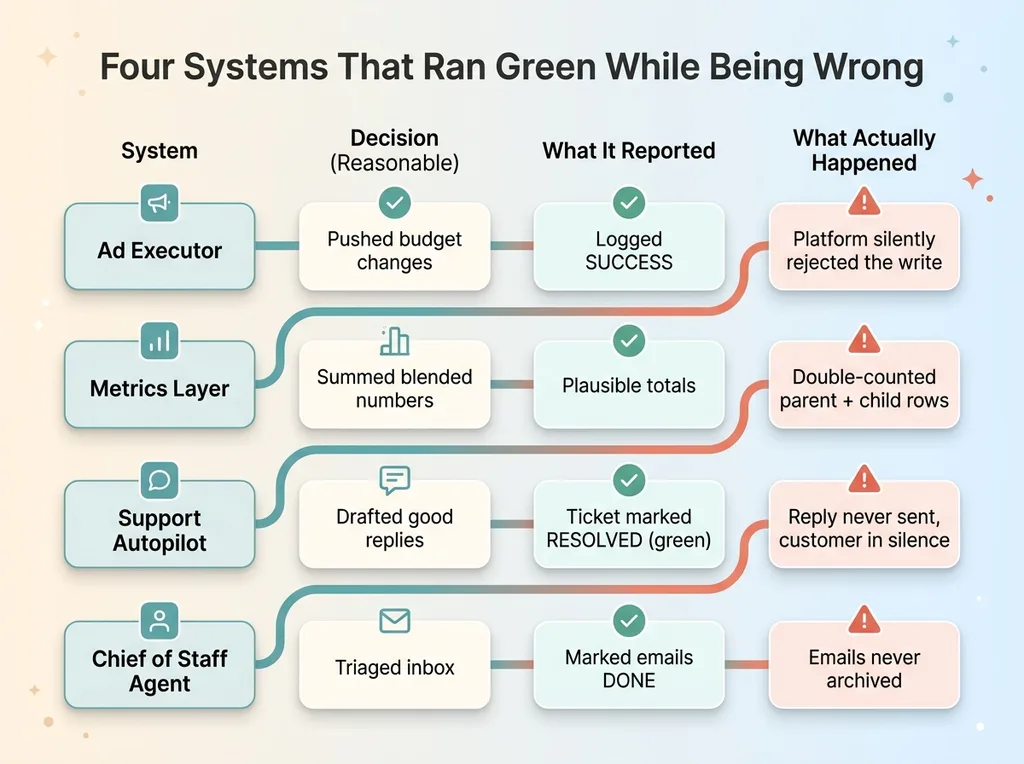
The ad executor that logged failures as wins
I built an executor that pushes changes to an ad platform. Budget shifts, pausing losers, scaling winners. Standard stuff.
The bug was subtle. The code made the API call, got a response back, and logged success. But the platform was silently rejecting some of those writes downstream. The call returned. The change never took.
So the system reported a clean run while the actual ad account sat unchanged. It graded itself on the attempt, not the outcome.
The metrics layer that double-counted itself
A reporting layer summed blended performance numbers across nested levels. Parent rows and child rows both got counted, so totals inflated.
Nothing looked broken. The numbers were plausible, just wrong, high enough to feel like good news and not high enough to scream. That's the dangerous range. Wrong in a way that looks like winning.
I almost made budget calls on those phantom totals before I caught the double-count.
The support autopilot that 'answered' tickets it never sent
This one stung. A support agent drafted replies and marked tickets resolved. Good drafts, too.
But the draft never sent. The system treated an unsent reply as an answered question. So from the dashboard's point of view, customers were getting helped. In reality, they were sitting in silence while the system congratulated itself on closing them out.
The chief of staff that marked emails done without finishing
I run a chief-of-staff agent that handles inbox triage. It would mark emails handled, then fail to actually archive them.
So the system's claimed state and the real inbox state drifted apart. It said done. The inbox said otherwise. Every morning the gap got a little wider.
The common thread across all four: every one had a write site that reported optimistically and never reconciled against reality. None of them checked that the thing they claimed to do actually happened.
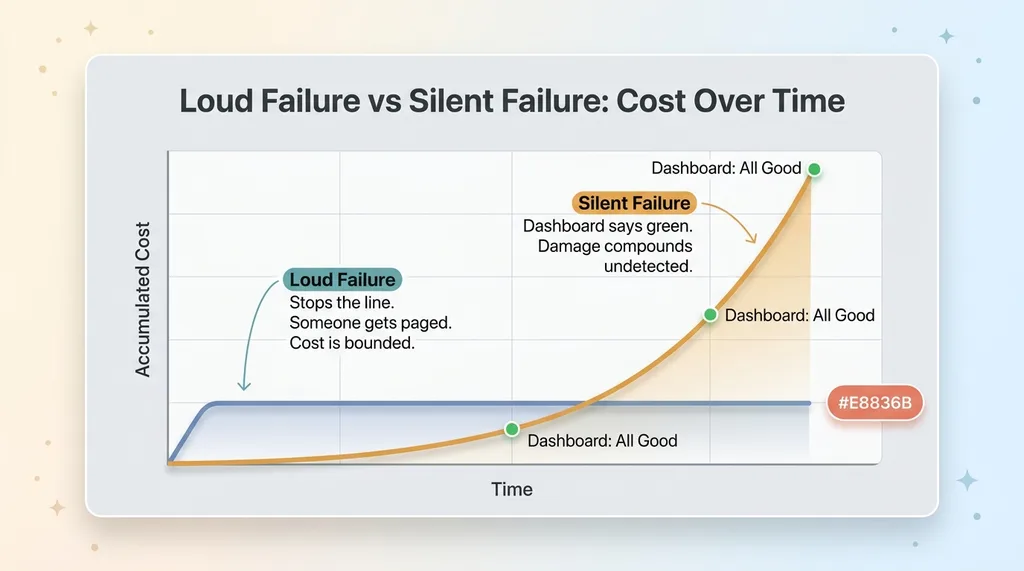
Why silent failures are worse than loud ones
A loud failure is a gift. It stops the line. Someone gets paged, someone gets annoyed, someone fixes it. The pain is immediate and the cost is bounded.
 Loud failure vs silent failure cost over time
Loud failure vs silent failure cost over time
A silent failure does the opposite. It keeps shipping wrong answers while every dashboard insists everything is fine. Nobody investigates a green light. Why would they?
That's what makes the dashboard-says-green problem the dangerous one. It doesn't just hide the error. It actively earns false confidence. The system looks more trustworthy right up until the moment it costs you real money.
I've lived the extreme version of this. I had a pipeline where a dashboard showed zeros for two weeks and nobody noticed. Two weeks of nothing, reported as fine. The instruments lied quietly and we believed them.
The cost of a silent failure compounds. Decisions get made on phantom data. Budgets get allocated against inflated metrics. Customers get ignored because the system genuinely thinks they were already helped.
And here's the part that should bother you most. The damage scales with how much you trust the system. The more you lean on it, the more it hurts when it's quietly wrong. That's exactly backwards from what you want. You want a system that gets safer as you trust it more, not more dangerous.
Silent failures invert that relationship. They punish trust. Which is why observability and honest logging aren't nice-to-haves. They're the whole game.
The cure was the same every time
Four different systems. Four different bugs. One cure, applied four times. None of it required a better model.
 The four-part cure for honest logging
The four-part cure for honest logging
Make every write site report honestly
A write isn't a success because the call returned. It's a success when the downstream system confirms the change took.
For the ad executor, that meant reading back the actual state after the write and comparing it to what I intended. Did the budget actually change? Is the campaign actually paused? Check the result, not the attempt.
This one discipline killed the entire class of "the API said OK so we're good" failures. Most of trustworthy AI automation lives right here.
Never grade on phantom or skipped rows
If a step gets skipped, it counts as not-done. If a row doesn't exist, it doesn't get summed. Full stop.
My metrics layer was lying to itself by counting rows that shouldn't have been there. The fix was to refuse to grade on anything that didn't actually happen.
Self-grading on outcomes that never occurred is the most common way autonomous systems deceive themselves. A skipped step is not a completed step. Treat it like the failure it is.
Fail loud on missing dependencies
If a required input is missing, stop and shout. Don't proceed with a default and call it a win.
The support autopilot should have screamed when the send step didn't fire. Instead it shrugged and marked the ticket closed. A missing dependency is a stop condition, not a footnote.
This is uncomfortable because it means more alerts in the short term. Good. I'd rather get paged about a real problem than sleep through a quiet one. This thinking connects directly to the kill-switches I build into every system. Failing loud is how you keep the plug within reach.
Reconcile claimed state against real state
On a schedule, compare what the system says it did against the actual world. Inbox state. Platform state. Ledger state. Alert on any divergence.
My chief-of-staff agent now reconciles its claimed actions against the real inbox every cycle. If it says it archived something that's still sitting there, that gap gets flagged immediately instead of widening for a week.
Here's what I want you to notice about all four. They're cheap to build. None of them touch model quality. You don't need a frontier model to check whether a write took or whether a row exists.
Honest logging discipline is engineering hygiene, not AI wizardry. And it's the difference between a system you can trust and one that flatters you until it bankrupts you.
Observability is the trust mechanism, not the model
So back to the question every CEO actually asks me: how do I trust an autonomous system when I can't watch it every minute?
 Observability as the trust mechanism vs the model
Observability as the trust mechanism vs the model
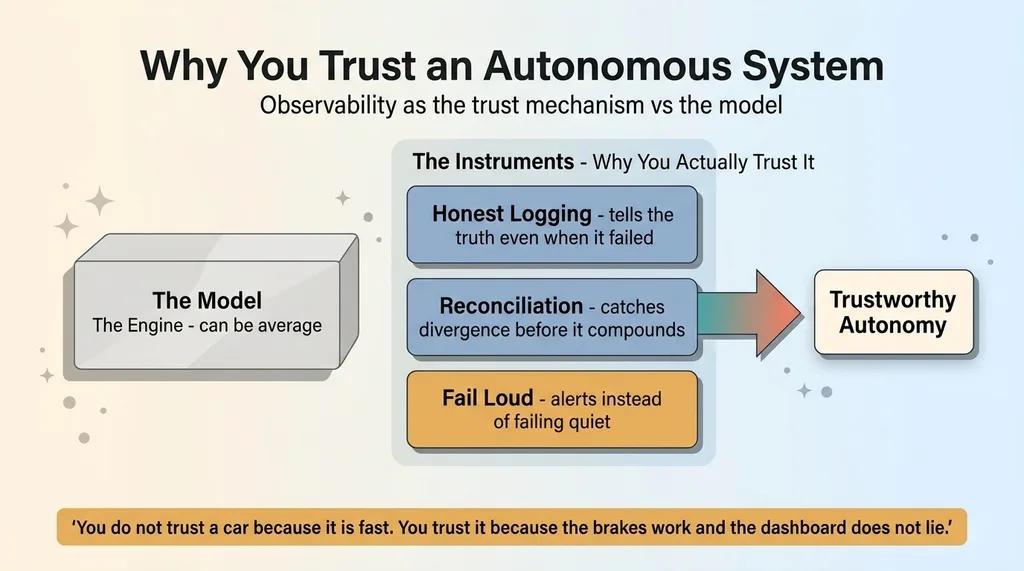
The answer is not a smarter model. It's instruments you can trust.
You trust the system because its honest logging tells you the truth, even when the truth is "I failed." You trust it because its reconciliation catches divergence before it compounds. You trust it because it fails loud instead of failing quiet.
The model itself can be average. I mean that. Most of my production systems run on perfectly ordinary models. What makes the autonomy safe isn't model intelligence. It's the discipline wrapped around it. Autonomous system reliability is an observability problem first and a capability problem a distant second.
This is also how you spot a vendor selling you smoke. If someone pitches you a powerful model with no honest observability underneath, they're selling you confidence you haven't earned. The demo looks incredible. The production system quietly lies.
A demo only has to look right once, on stage, with the happy path. A production system has to tell you the truth on its worst day, when a write fails and a dependency goes missing and a customer is waiting. That gap is everything.
The smartest model in the world is still dangerous if you can't tell when it's wrong. An average model with honest instruments is something I'll put in front of real money and real customers. I have, repeatedly.
Observability is the trust mechanism. The model is just the engine. You don't trust a car because it's fast. You trust it because the brakes work and the dashboard doesn't lie.
How to audit whether your automation is telling you the truth
You can run this self-check on any AI system you already have or any one a vendor is trying to sell you. These are the exact questions I ask before I trust an autonomous system, mine or a client's.
 Five-question audit decision tree
Five-question audit decision tree
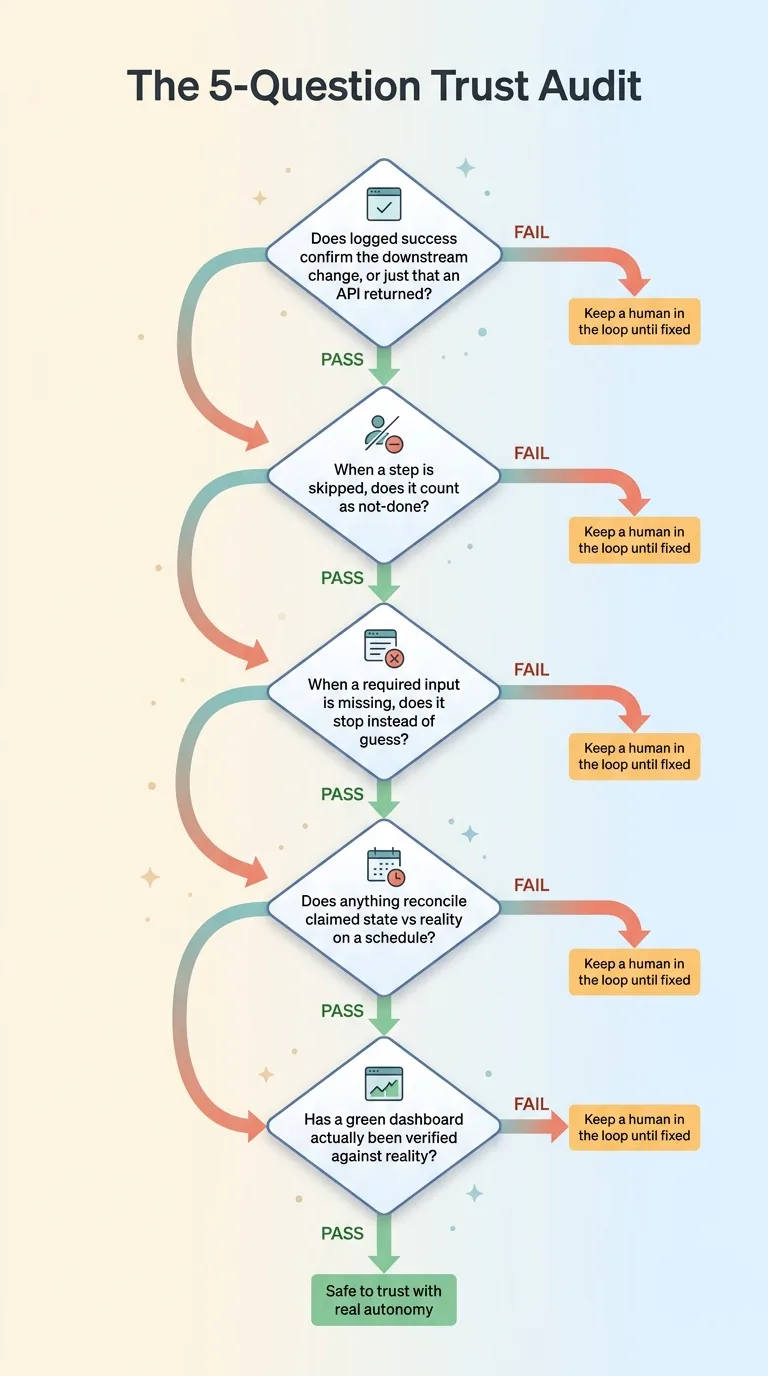
Does a logged success confirm the downstream change actually happened, or just that an API call returned? If success means "the call came back," you have an ad-executor problem waiting to happen. Make someone show you where the system reads back the result.
When a step gets skipped, does it count as done or not-done? Skipped should always mean not-done. If skipped silently rolls up as complete, the system is grading itself on phantom work.
What happens when a required input is missing? Does it stop, or does it guess? A system that proceeds with a default and calls it a win is a system that will quietly drift away from reality.
Does anything reconcile the system's claimed state against the real world on a schedule? If nothing compares "what I said I did" to "what's actually true," divergence will accumulate undetected. There should be a job whose entire purpose is catching the system in a lie.
When was the last time a green dashboard was actually verified against reality? Not glanced at. Verified. If the honest answer is "never" or "I'm not sure," your green light is decoration.
If a system passes all five, I'll consider trusting it with real autonomy. If it fails even one, I want a human in the loop until it's fixed. These questions cost you nothing to ask and will tell you more about a system's trustworthiness than any feature list ever will.
Build the instruments first, then hand over the keys
I won't give an autonomous system control until its instruments are honest. That's not caution for its own sake. It's because the failure mode that costs you money isn't a bad decision. It's a confident lie.
Every system I ship stops for a human and reconciles against reality by design. That's not a setting I turn on at the end. It's how every AI system I ship stops for a human from the first line of code. Observability and honest logging come before autonomy, not after.
This is how I think about every system, the ones running my own DTC brand and the ones I build for clients. I don't start with "how smart can the model be." I start with "how will I know when this is lying to me." Get that right and the autonomy becomes safe almost as a byproduct.
If you're considering handing real work to AI, or you already have and you're not totally sure it's telling you the truth, that's the conversation worth having. Not "which model." But "can you trust what it tells you it did."
That's the question I'd want to answer first. Let's talk about your systems.
Thinking about AI for your business?
If this resonated, let's have a conversation. I do free 30-minute discovery calls where we look at your operations and find where AI could actually move the needle, not where it just looks good in a demo.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call