Redundant Automation Systems Drift: A Hidden AI Tax
I built two monitors for the same job and they started disagreeing. The story of redundant automation systems drift and the consolidation debt nobody warns you about.
By Mike Hodgen
The Day Two Systems Gave Me Opposite Answers
One Tuesday morning I had two emails sitting in my inbox from the same address, both about the same thing, and they completely disagreed with each other.
I run a DTC fashion brand out of San Diego. Part of keeping that brand healthy is watching for toxic referring domains, the spammy backlinks that show up when someone decides to point a few hundred garbage sites at you. Those domains need to go into a disavow file so Google ignores them.
I had two independent systems watching for exactly that. One email said a specific domain was a threat and should be disavowed. The other said the same domain was clean. Same underlying data. Opposite verdicts.
I sat there with my coffee thinking the only thought that matters in that moment: which one do I trust?
Here's the part that took me a second to accept. This was not a bug. Neither system was broken. Both of them did precisely what I built them to do. The cloud job ran its logic and reached its conclusion. The local job ran its logic and reached a different one. They were both working as designed.
The problem wasn't either system. The problem was that I had two of them doing one job.
This is the part of building with AI that nobody puts in the pitch. When you can ship a system in an afternoon, you ship a lot of them. And redundant automation systems drift apart quietly until the day they collide on a specific case and force you to figure out which of your own creations was lying to you.
That morning was the day my hidden AI tax came due.
How I Ended Up With Two Monitors for One Job
I never decided I wanted two monitors. It accreted, one reasonable decision at a time.
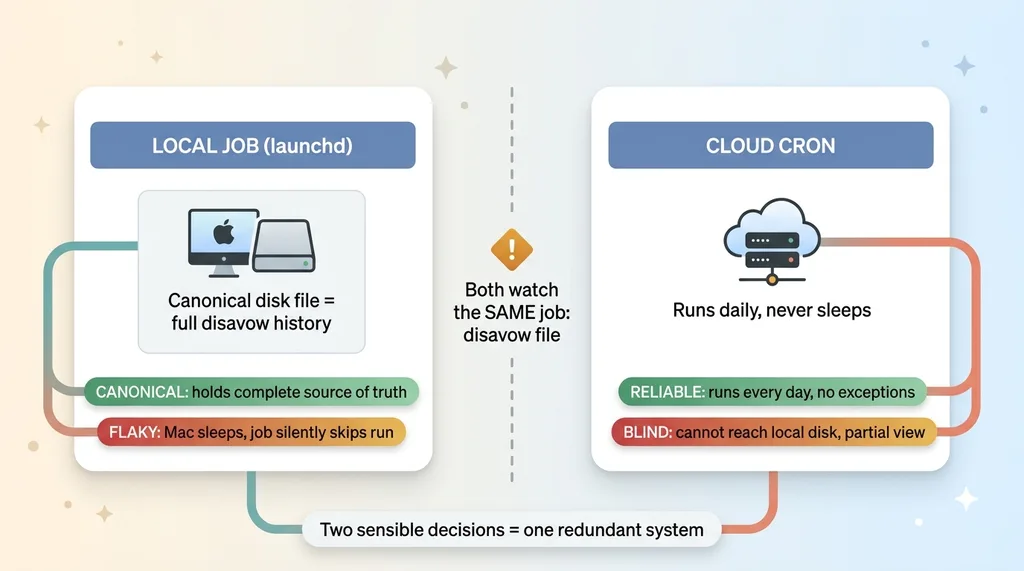 Two redundant monitoring systems with opposite trade-offs
Two redundant monitoring systems with opposite trade-offs
The cloud cron that's reliable but blind
I built the first pipeline as a local scheduled job. On a Mac, that means launchd. It holds the canonical, complete disavow list on local disk. That file is my source of truth, the full union of every domain I've ever decided to disavow.
It works great when the machine is awake. The problem is a Mac sleeps. When it's asleep, launchd silently skips the run. No error, no email, just a missed day. I'd go to bed, the machine would doze off, and the canonical job wouldn't fire.
I didn't notice for a while because nothing tells you about a job that didn't run. Silence is not success, and back then my monitoring wasn't honest enough to flag the gaps.
The local job that's canonical but flaky
Months later, building fast, I solved the missed-run problem the obvious way. I spun up a cloud cron. Cloud jobs don't sleep. This one runs reliably every single day, no exceptions.
But the cloud job can't reach my local disk. That's where the full canonical file lives. So the cloud job had a partial view of the world. It knew about new candidate domains it detected on its own, but it didn't have the complete history that the local job held.
So now I had two monitors. The local one was canonical but flaky. The cloud one was reliable but blind. Neither was wrong in isolation. Each one was a sensible response to a real problem.
That's how redundant systems are born. Not by design, by velocity. This is what fast AI-first building actually looks like: you solve the problem in front of you, ship it, and move on. Repeat that enough times and you wake up with two systems quietly disagreeing.
Why Redundant Automation Systems Drift Apart
Redundant automation systems drift when two independent processes solve the same problem against slightly different inputs, run on different schedules, and evolve separately over time.
 The three conditions that guarantee drift
The three conditions that guarantee drift
That's the whole phenomenon in one sentence. Each system starts out reasonable. Each one gets patched in isolation. The cloud job got a tweak one week to handle a new domain pattern. The local job got a different tweak another week to change how it scored candidates. Nobody reconciled the two changes because nobody was thinking of them as one system.
Over time the two diverge until they produce contradictory output on the same input. The drift is invisible right up until they collide on a specific case, which is exactly what happened in my inbox that Tuesday.
There are three conditions that guarantee this drift. When all three are present, disagreement isn't a risk. It's a matter of when.
- Overlapping responsibility. Two systems own the same job. Both decide what belongs in the disavow file.
- Divergent data access. They see different inputs. The local job had the full canonical list. The cloud job had a partial view.
- Separate maintenance. They get patched independently, on different days, by whoever is solving whatever broke that week.
Overlap means they're answering the same question. Divergent data means they're working from different facts. Separate maintenance means the gap between them widens every time you touch one without touching the other.
This is the core of what I call consolidation debt, and I've written before about two monitors that started disagreeing. It's debt because it accrues silently and you pay it all at once, usually at the worst possible time. The longer two redundant systems run, the further apart they drift, and the more expensive the eventual reconciliation gets.
The Constraint That Made 'Just Append the New Lines' a Trap
Here's the detail that turned a cosmetic annoyance into a real problem.
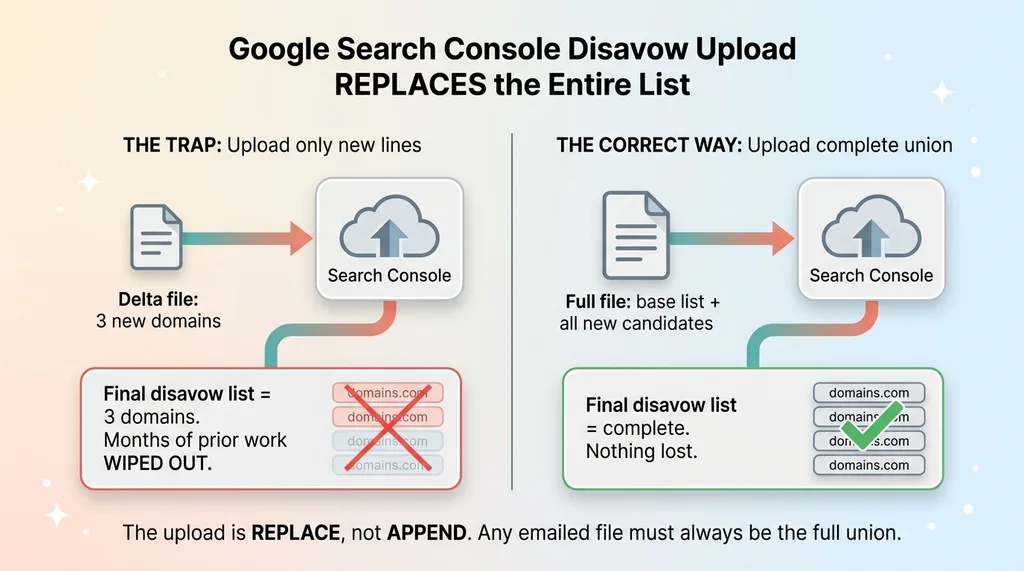 Why uploading a partial disavow file destroys your work (replace not append)
Why uploading a partial disavow file destroys your work (replace not append)
The disavow upload to Google Search Console replaces the entire list. It does not append. When you upload a file, that file becomes the complete disavow list, full stop. Anything not in the file you upload is no longer disavowed.
Sit with that for a second, because the intuitive design is a trap. Your instinct is to build a system that emails you "here are the new toxic domains to add." That feels right. New threats came in, here's the delta, go add them.
But if I upload a file containing just the new lines, I wipe out everything I disavowed before. Every domain I'd flagged over months of monitoring, gone, because the upload replaced the full list with my tiny delta of new candidates.
So any file either system emails me has to be complete. It has to be the full union of the base list and every new candidate, every time. Not the delta. The whole thing.
This is the kind of domain constraint that bites you precisely because it's counterintuitive and undocumented in your own head. You don't write it down because it feels obvious in the moment. Then six months later you've forgotten it, and the natural design that any reasonable person would build is the one that quietly destroys your work.
It also explains why the cloud job's partial view wasn't cosmetic. The cloud job couldn't reach the canonical file, so the file it would have emailed me was incomplete. If I'd uploaded that partial file, I wouldn't have just had a system that disagreed. I'd have had a system that silently undid months of disavow work.
The constraint amplified the drift. Two systems disagreeing is annoying. Two systems disagreeing where one of them produces a destructive output is a real problem.
The Fix, and the Debt I Chose Not to Pay Yet
I fixed this in two parts, and I want to be honest about what I actually fixed versus what I deferred.
Patching both systems to agree
Short term, I made the cloud job attach the complete file every time. Base list, union all candidates, full union, no exceptions. Now it physically cannot email me a partial list. Even if it can't reach the local canonical file, it reconstructs the most complete file it can and never ships a delta.
Then I made the local rebuild fold review-grade candidate domains into the canonical file by default. So the source of truth stays current instead of lagging behind whatever the cloud job had detected.
The result: both systems now produce complete, compatible output. Upload either file and you're safe. They agree.
Naming the consolidation debt out loud
Here's the honest part. I didn't actually fix the root problem. I still have two systems doing one job. I patched them to agree today. That is not the same as solving it.
The real fix is consolidating to one system with one source of truth and one schedule. Until I do that, the three conditions for drift are still present. Overlapping responsibility, divergent data access, separate maintenance. They agree right now because I just touched both. Give it a few months of independent patches and they'll drift again.
So I documented the consolidation as open debt. Deliberately. In writing. Because the original duplication happened precisely because nobody wrote down that there were two systems. The duplication got forgotten, and forgotten debt becomes a landmine.
This is what I mean by agentic dev hygiene. When you build fast, you have to write down the debt you're deferring, or speed turns into a series of buried surprises. Naming the debt doesn't pay it. But it keeps it from ambushing you, and it gives you the choice of when to pay rather than having that choice made for you at 7am on a Tuesday.
The Maintenance Tax Nobody Quotes You When AI Makes Building Cheap
When AI lets you build a system in an afternoon, the cost of creating a system collapses. The cost of owning it does not.
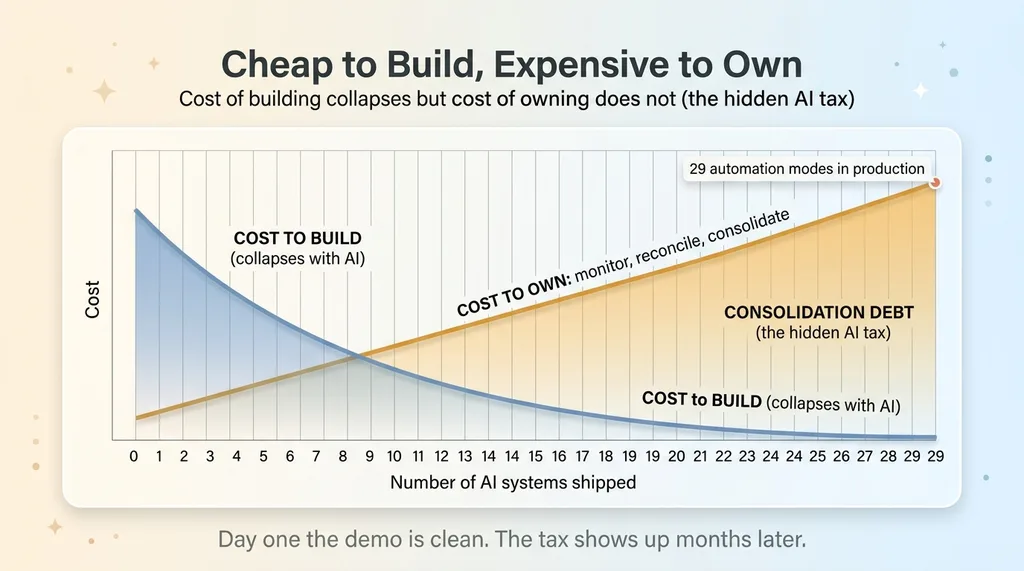 Cost of building collapses but cost of owning does not (the hidden AI tax)
Cost of building collapses but cost of owning does not (the hidden AI tax)
That's the whole thing. Everyone is dazzled by how cheap building has become. I've built 15-plus AI systems for my own brand and I'm running 29 automation modes in production. I can go from idea to working pipeline faster than I can write the spec by hand. That's real and it's wonderful.
But every system you ship is something that has to be monitored, reconciled, and eventually consolidated. The cheaper creation gets, the easier it is to accidentally build two things that do one job, because spinning up the second one feels free in the moment.
The hidden tax of fast, agentic development is consolidation debt. It doesn't show up on day one. Day one everything works, the demo is clean, the new system does exactly what you asked. The tax shows up months later, when two of your own systems disagree and you're standing in your inbox trying to figure out which one was lying.
My honest take: this is real, and it's the price of speed. The answer is not to build slower. Slow building has its own costs, and they're usually worse. Speed is the right call.
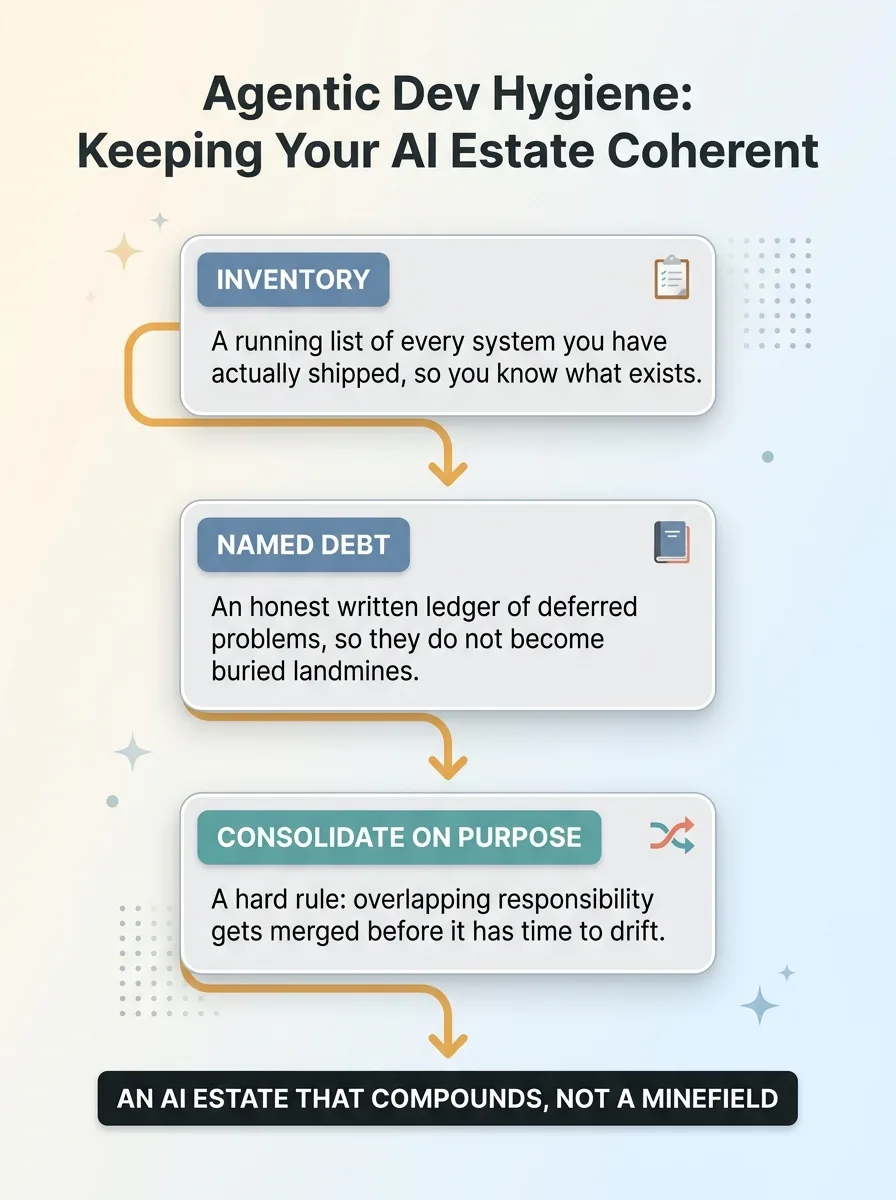
The answer is disciplined hygiene. Three things, specifically. An inventory of what you've actually shipped so you know what exists. Named debt so deferred problems don't become buried ones. And a hard rule that overlapping responsibility gets consolidated before it has time to drift. Two systems that do one job get merged on purpose, not patched into temporary agreement forever.
That discipline is unglamorous. It doesn't demo well. But it's the difference between an AI estate that compounds and one that quietly turns into a minefield.
Who Should Own Your AI Systems After They Ship
Most companies hire someone, or a vendor, to build AI systems. Almost nobody thinks about who reconciles them six months later, when there are fifteen of them quietly drifting apart.
 Disciplined AI hygiene: three practices to prevent drift
Disciplined AI hygiene: three practices to prevent drift
That's the gap. The build is the easy, visible part. The hard part is keeping the systems you already have honest with each other. Knowing what overlaps. Knowing what's deferred. Knowing which undocumented constraint is going to bite you the day you forget it exists.
I run 29 automation modes in production for my own brand, and I'll tell you straight: the discipline that keeps them from contradicting each other is as important as the builds themselves. Maybe more. A system that lies to you is worse than no system, because you act on it.
As a Chief AI Officer, that's the part of the job that actually protects you. Not just shipping new things. Keeping the estate coherent. An inventory of what exists, an honest ledger of what's deferred, and the judgment to consolidate before drift turns into a 7am surprise.
If your board is asking about AI and you're worried about the maintenance reality nobody mentions in the pitch, that's exactly the conversation I'm built for.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call