Returns System Migration: Bridging the In-Flight Gap
A returns system migration left 506 open returns invisible to the warehouse. Here is the scan-fallback and backfill that let any open return get received.
By Mike Hodgen
The Day the Warehouse Couldn't Scan a Box
A worker on the floor picks up a returned package. Scans it. The receiving screen searches the new returns table, looking for a matching row to receive against.
Nothing.
The box is real. It's sitting in her hand. There's a packing slip inside, a customer who shipped it back, and a refund that customer is already expecting. But the system says the return doesn't exist. So the box stalls. It gets set aside on a shelf labeled "figure out later," which is where good intentions go to die in a warehouse.
This is what "switching systems" actually looks like at ground level. Not a clean cutover slide. A person holding a physical object the software refuses to acknowledge.
We had just moved returns onto a new portal tied to the warehouse OS. The migration was clean on paper. Every new return created from the cutover date forward landed in the right place and processed perfectly. The problem was everything created before that date, or created somewhere else entirely.
We had 506 open returns in flight. Of those, 50 were stranded under 90 days, meaning real customers had genuinely shipped boxes back and were waiting on us. Some of those returns were born in the old returns app. Some started as Shopify native returns. A handful were manual refunds a customer service rep had set up by hand.
None of them had a matching row in the new system.
The gap was completely invisible until a human held a box that couldn't be processed. No error log fired during the migration. No dashboard turned red. The data was technically fine. It just lived in a place the new tool didn't know to look.
That's the returns system migration problem in one scene. And it's the same shape in every migration I've ever seen.
Why Migrations Strand Your In-Flight Work
The new tool only knows what it created
Here's the thing nobody tells you when you buy a new system: it only searches its own table.
The new returns portal knew about every return it created. It had zero awareness of returns created before it existed, or returns created in a parallel channel running alongside it. To the new system, those returns weren't "old data." They simply weren't real.
That's not a bug. It's just how software works. A tool resolves against the truth it owns. Anything outside that boundary is a ghost. It exists in reality and in the old system, but the new one has no pointer to it.
Three places a return could have been born
In our case, a return could have come from three different origins:
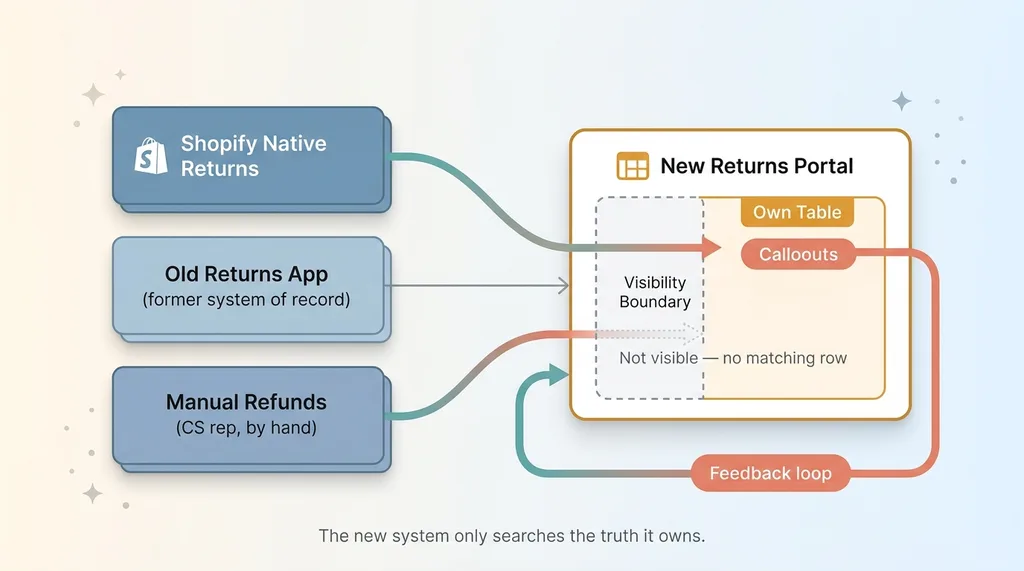 Three origins of a return feeding into one new system
Three origins of a return feeding into one new system
- Shopify native returns, created directly through the store's built-in return flow
- The old returns app, which had been the system of record before the migration
- Manual refunds, set up by hand by a customer service rep solving a one-off
Three birthplaces. One new system that only understood one of them.
This is true of any migration, not just returns. Swap "returns" for CRM contacts, billing subscriptions, or inventory counts and the story is identical. When you have two systems that both think they own the truth, the cracks don't show up in testing. They show up three weeks later when a person hits one.
The mistake almost everyone makes is treating this as a one-time data dump. Migrate everything once, cross your fingers, and hope nothing leaked. But a one-time migration can't catch a return that gets shipped back the day after cutover from an order placed the week before.
The fix is never "migrate the data once and pray." It's a bridge that can resolve any in-flight item, from any origin, on demand.
The Scan-Fallback: Import on a Miss
The core fix was simple to describe and careful to build. When the receiving scan can't find a return in the new system, it doesn't error. It goes looking.
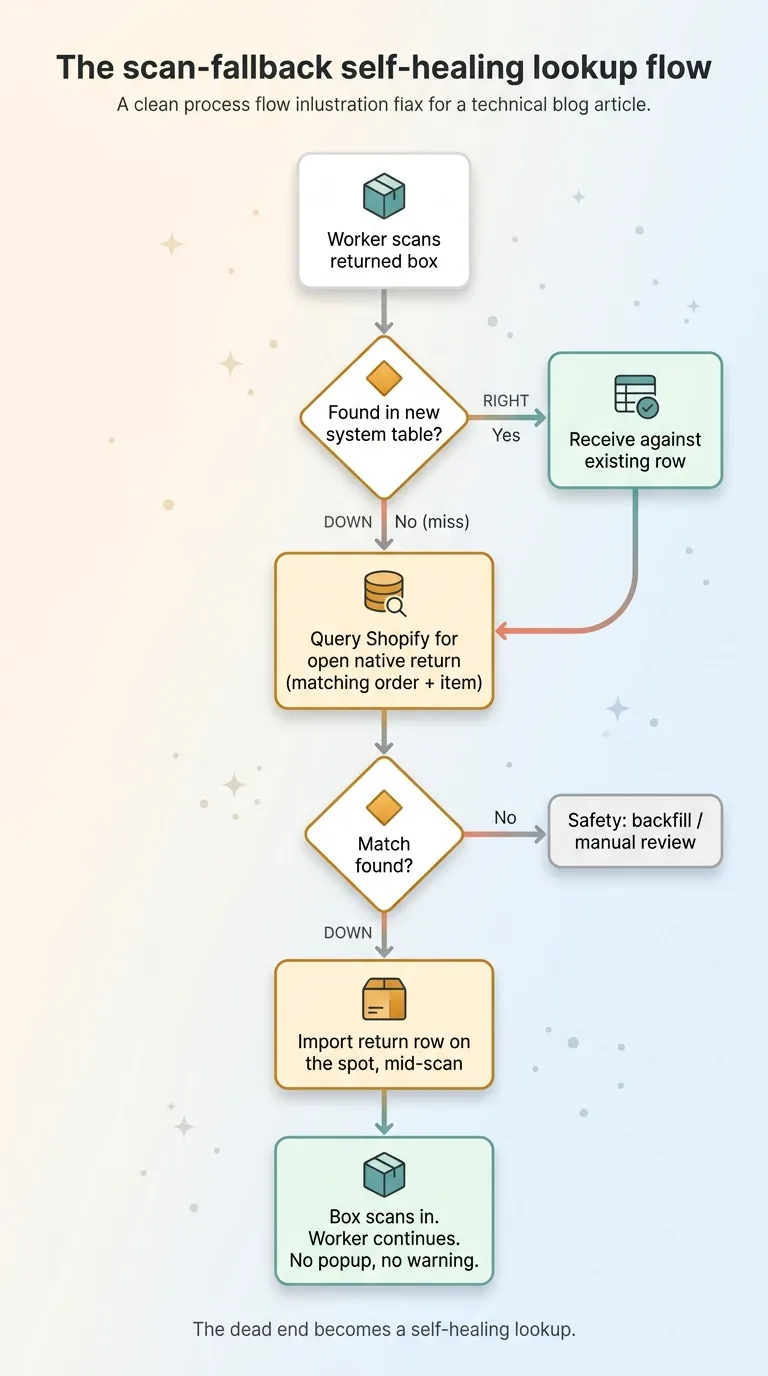 The scan-fallback self-healing lookup flow
The scan-fallback self-healing lookup flow
Here's the flow. The worker scans the box. The new system checks its own table, finds nothing. Instead of throwing an error and stalling, it turns around and queries Shopify for an open native return matching that order and that item.
If one exists, it imports it on the spot. Right there, mid-scan, it creates the row the warehouse needs to receive against. The box scans in. The worker moves to the next package.
She never knows anything unusual happened. There's no popup, no "this return came from the old system" warning, no manual lookup. The dead end becomes a self-healing lookup.
The design principle behind this matters more than the code. The scan should never fail just because the data lives somewhere else. A warehouse worker's job is to receive boxes, not to reconcile two databases. If the system makes her the casualty of a migration gap, you've built the wrong system.
So I made the warehouse the resolver of the gap, not its victim. When the new system comes up empty, it reaches into the place the data actually lives, pulls it forward, and keeps the line moving.
This handles the unpredictable case beautifully: a return that comes in tomorrow for an order that predates the cutover. No backfill could have anticipated that specific box. The scan-fallback doesn't need to. It resolves the return at the exact moment a human needs it resolved, which is the only moment that counts.
Backfill, Then Close Out the Stale Ones
The scan-fallback handles returns as they physically arrive. But I didn't want to wait for 506 boxes to trickle in over weeks before the new system knew they existed. That's where the cleanup came in, and it had two parts.
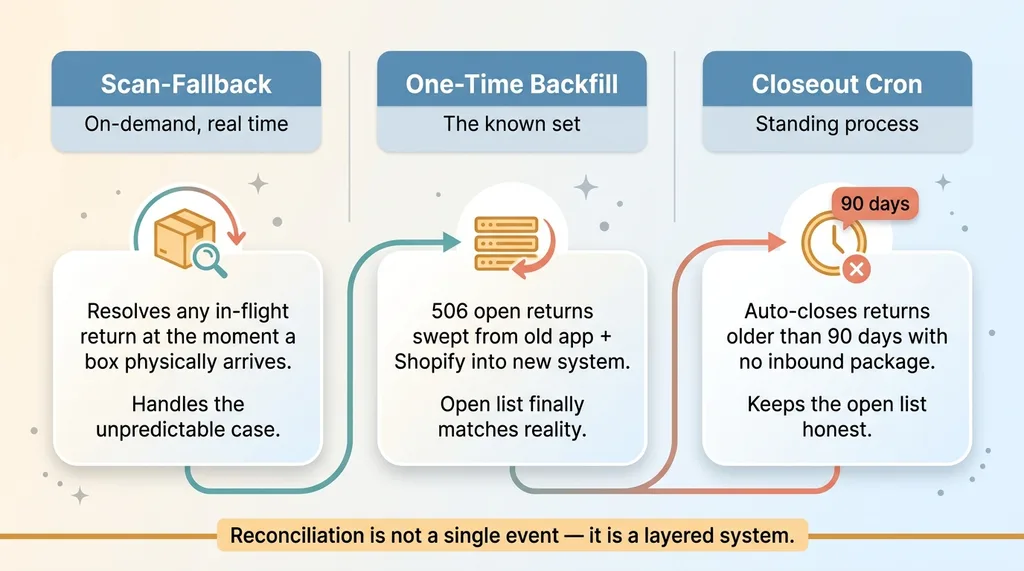 Three-layer reconciliation strategy (fallback, backfill, closeout cron)
Three-layer reconciliation strategy (fallback, backfill, closeout cron)
A one-time backfill for the 506 open returns
I wrote a backfill script that swept all 506 open returns out of the old returns app and out of Shopify, then created matching rows in the new system. No waiting for a scan to trigger the import.
After the backfill ran, those returns resolved instantly when a box hit the receiving station. The scan-fallback was still there as a safety net for anything the sweep missed, but the bulk of the known in-flight set was now visible to the new system. The open-returns list in the new portal finally matched reality.
A cron to close out anything past 90 days
The second part dealt with the long tail. A big chunk of "open" returns are returns customers initiated and then never shipped back. They sit open forever. Without something to close them out, the open-returns list grows without bound, and nobody can tell a real pending return from abandoned noise.
So I built a closeout cron. Any return older than 90 days with no inbound package gets automatically closed. The list stays honest. A human looking at it can trust that everything still open is something that actually needs attention.
This is the quiet residue left behind by a migration that most teams never clean up. The cutover finishes, everyone celebrates, and six months later the open-returns report is 70% dead entries nobody can interpret.
Reconciliation isn't a single event. It's a backfill for the known set, plus a standing process that keeps the data honest after everyone's stopped paying attention.
Real Receiving: Restock, Hangtag, and Store Credit
Bridging the data is necessary but not sufficient. Once the return resolves in the system, the physical and financial actions have to actually happen. A status flip that doesn't move real inventory or credit a real customer is just a lie with a green checkmark.
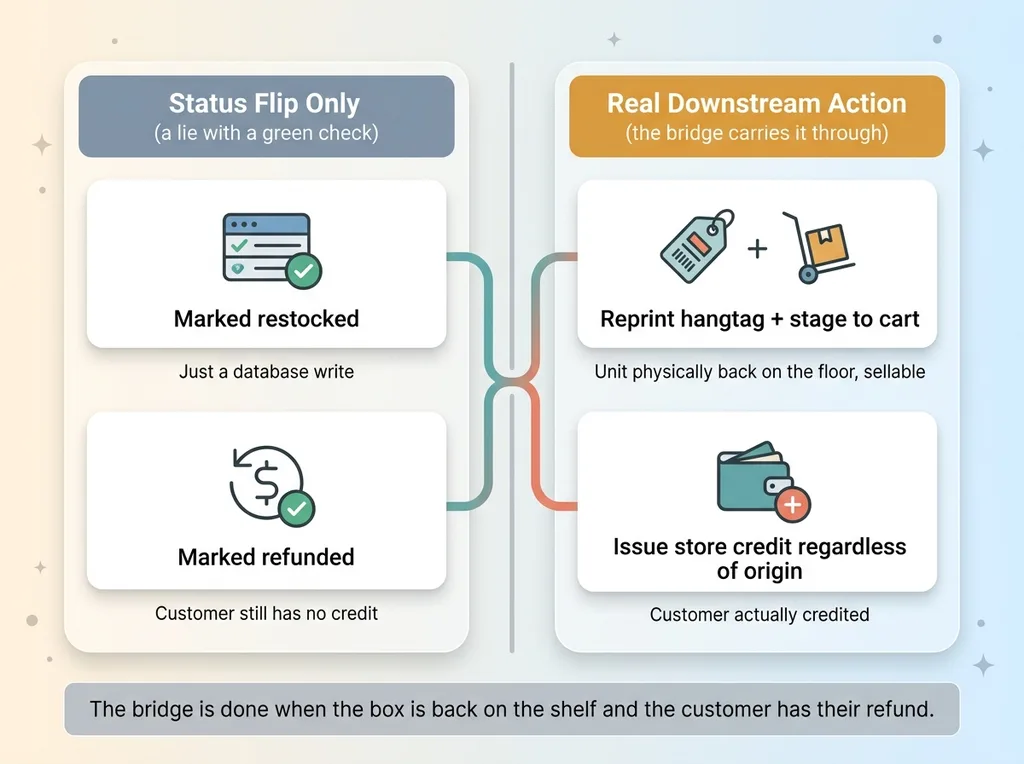 Status flip vs real downstream action (restock + store credit)
Status flip vs real downstream action (restock + store credit)
Restock that reprints a hangtag and stages to the cart
When a returned item gets restocked, the system does the real thing. It reprints a hangtag for the unit and stages it to the warehouse cart so it physically re-enters sellable inventory.
That's the difference between "marked as restocked" and "actually back on the floor." A status change is a database write. A reprinted hangtag and a staged cart is a unit a customer can buy again. Our products are handmade in San Diego, so every unit that gets stranded in returns limbo is real margin sitting on a shelf doing nothing.
Store credit for returns that didn't start in the portal
The financial side had its own gap. A customer whose return started in Shopify or in the old app still needed to get credited correctly, even though the return didn't originate in the new portal.
So store credit issuance works regardless of where the return was born. The bridge doesn't just import the row, it carries the downstream financial action with it. The customer gets their credit. They never know or care which system the return passed through.
This is the full picture I cover in the returns intake system I rebuilt, which runs on the warehouse production OS I built and replaced four separate SaaS tools.
The lesson is blunt: a migration bridge has to reproduce every downstream action. Import the row but skip the restock, and you've just moved the gap one step further down the line. Import the row but skip the credit, and a customer is out money. The bridge isn't done when the data matches. It's done when the box is back on the shelf and the customer has their refund.
Why Every Path Is Idempotency-Locked
Now look at what I'd built. Three different things could touch the same return: the scan-fallback could import it, the backfill could import it, and the cron could close it. Three entry points, one return.
That's a recipe for double-processing. Credit a customer twice. Restock the same physical unit twice, inflating inventory. Import a duplicate row that shows up as two pending returns for one box.
So every path is idempotency-locked.
Idempotency is a fancy word for a simple idea: running the same operation twice produces the same result as running it once. If the backfill already created a row for return #4471, running the backfill again does nothing. If a box was already restocked, scanning it a second time doesn't restock it again. If a customer already got their store credit, no path can issue it twice.
This is the unglamorous part that actually decides whether a migration bridge is safe. It's not exciting. There's no demo for "we successfully did nothing the second time." But it's the difference between a tool you can trust and a tool that quietly corrupts your books.
Here's the principle I keep coming back to: a clean import that double-refunds is worse than no import at all. At least with no import, you know you have a gap and a human is watching for it. A double-refund happens silently, looks successful, and you find it in an accounting review three months later.
When you let multiple processes touch the same record, idempotency isn't optional. It's the whole game.
What This Means When You Switch Systems
When you switch systems, your in-flight work doesn't vanish. But it does go invisible unless you plan for it.
That's the trap. The migration looks finished. New records flow into the new system perfectly. The dashboard is green. And meanwhile every return, invoice, ticket, or order that was already in motion at the moment of cutover sits in a blind spot, waiting for a human to physically run into it.
The answer is a layered one, and it's the same shape no matter what you're migrating. A bridge that can resolve any open item from any origin, on demand. A backfill for the known set so you're not waiting on accidents. A standing process to close out the long tail so the data stays honest. And idempotency on every path so nothing gets processed twice.
Most vendors hand you a clean cutover date and a migration script that runs once. The in-flight work is your problem. It leaks through the cracks one box, one invoice, one angry customer email at a time, and the cost shows up as labor and lost trust long after anyone connects it to the migration.
I build the bridge that catches it. The scan-fallback, the backfill, the closeout, the idempotency locks, and the downstream actions that make the data mean something in the real world.
If you're staring down a system switch and worried about what happens to everything already in motion, that's exactly the kind of gap I close. Bring me in to bridge it.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call