I Built a Polished App in a Weekend. Here's How.
How I built a complete consumer app in a weekend: passwordless auth, live auto-scoring, and a 3D trophy. Proof that polished apps no longer take months.
By Mike Hodgen
The tournament started tomorrow, so I had one weekend
The bracket dropped Friday. First games tipped off Saturday afternoon. And I had decided, for no good reason other than I wanted to, that my extended family needed a prediction pool to argue over for the next three weeks.
The constraints were brutal in the way that makes you focus. No time to ship to an app store and wait on review. No time to set up a system where I'd be resetting passwords for my aunt every other day. The forcing function was the calendar, not the spec.
So the question became: can I build app in a weekend that is actually polished, actually live, and dead simple for non-technical relatives to use? Not a hackathon prototype with three console errors and a "demo only" caveat. A real consumer app that updates itself when games finish.
I did. Over two days, solo, I shipped a free family prediction pool with passwordless sign-in, a scoring engine that grades picks automatically, live score updates pulled from a public API, and a 3D trophy on the leaderboard because why not.
Here is the part CEOs need to hear. Most of you assume something like this takes months and a team of engineers. That assumption was correct three years ago. It is wrong now, and the gap between what you think a build costs and what it actually costs is probably the most expensive thing on your roadmap.
I'm going to walk through exactly what got built, the real engineering decisions behind it, and why the timeline collapsed. Not to brag about a family game. To show you where your six-month estimate is hiding three weeks of actual work.
What "dead simple" actually requires under the hood
The product requirement sounded trivial when I wrote it down. A relative should be able to open a link, enter their name, make their picks, and be done. No password. No app download. No friction.
That sentence is where all the real work hides.
No accounts for relatives
My target user is someone who texts in all caps and has never knowingly created an account for anything. If the first screen asks for a password, half the family bounces before making a single pick. Adoption dies at the friction point, and for a free family pool, any friction at all is too much.
So the user-facing requirement was zero friction. Open link, play. That part is easy to state and hard to deliver.
But scores still have to be right
Here is the tension. Even though the user does nothing more than type a name, the system still needs a stable, unique identity for each player. The scoring engine has to know whose picks are whose, permanently, with no ambiguity.
And that identity has to survive real-world behavior. Someone makes their picks on their phone Saturday morning. Sunday they want to check standings on a laptop. If the laptop treats them as a brand-new player, now I have two ghost copies of the same person and a leaderboard that makes no sense.
This is the thing people miss about consumer UX. "Simple for the user" almost always means "harder for the builder." The friction you remove from the front end has to go somewhere, and it goes into the architecture. You absorb the complexity so the user never sees it.
That is the actual job. Not making it look easy. Making it be easy while the hard parts run quietly underneath.
Passwordless identity that works across devices
The answer was passwordless authentication, which is the right default for any consumer app where account management friction kills adoption. Nobody wants another password. Half of them won't remember it, and every password you store is something you can leak.
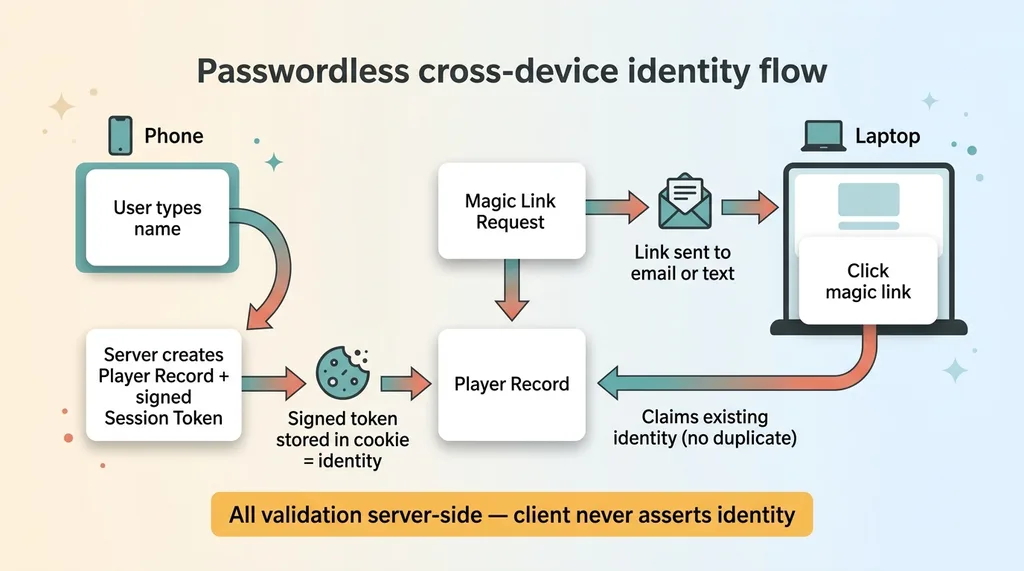 Passwordless cross-device identity flow
Passwordless cross-device identity flow
Sign up creates a player and a session
When someone joins, the system creates a player record and drops a signed session token into a cookie on their device. That cookie is now their identity. No password to remember, no password to reset, no password to steal.
From the user's side it feels like nothing happened. They typed a name and started picking. From the system's side, that device is now reliably tied to one specific player, and every pick they make is attributed correctly.
Magic links to claim on a second device
The cross-device problem gets solved with a magic link. If you want to play from a second device, you request a link, it lands in your email or text, and clicking it claims your existing identity on the new device instead of spawning a duplicate.
Same player, two devices, one consistent record. The leaderboard stays clean.
The part that matters for anyone building this for real: all of it is validated server-side. A session token in a cookie can't be hand-edited to impersonate another player, because the server checks and signs everything. The client never gets to assert "I am player 7" and have the system believe it. Trust lives on the server, never in the browser.
This is the same pattern I'd use for any consumer app, family game or not. Passwordless is not a shortcut. Done correctly, it is more secure than passwords and removes the single biggest reason casual users abandon a product before they ever use it.
A scoring engine that can't get confused
The scoring engine was the part I cared most about getting right, because a prediction pool that scores wrong is worse than no pool at all. Nothing ends a family game faster than an argument about whether the standings are correct.
Why I made it recompute from scratch
The obvious way to build scoring is incremental. A game finishes, you add points to whoever picked correctly, you move on. It feels efficient.
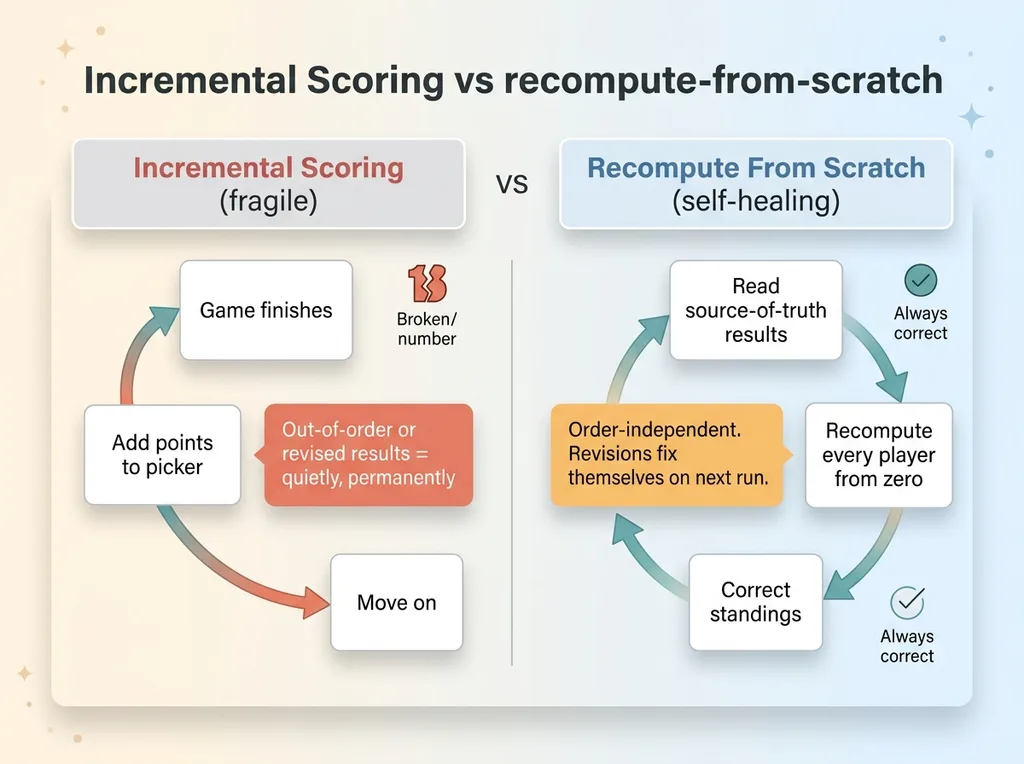 Incremental scoring vs recompute-from-scratch
Incremental scoring vs recompute-from-scratch
It is also fragile. Results don't always arrive in clean order. Sometimes a score gets corrected after the fact. With incremental scoring, an out-of-order event or a revised result leaves you with points that are quietly, permanently wrong, and you have no clean way to know.
So I built it the other way. The engine never adds points incrementally. Every time it runs, it recomputes every player's entire score from scratch, directly from the source-of-truth results.
Order-independent by design
That one decision makes the whole thing order-independent and self-healing. Results can arrive in any sequence. A score can get revised an hour later. None of it matters, because the next recompute just looks at the current truth and produces the correct answer from the ground up.
If the official result of a game gets corrected, I don't write a patch or a reconciliation script. The recompute handles it. The wrong number simply ceases to exist on the next run.
This is a small example of a principle I apply to everything: deterministic math should be deterministic, and you should make it impossible for the system to be subtly wrong. The expensive failures are never the loud ones. They're the quiet "off by a little" errors nobody notices until someone screenshots the standings and asks why.
The tradeoff is that recomputing from scratch costs more compute than incrementing. For a family pool with dozens of players, that cost is nothing. And I would happily pay it ten times over for the guarantee that the scores are always correct. Correctness over cleverness. That choice has never once let me down.
Live auto-scoring from a free public API
The thing that makes it feel alive is that nobody has to enter scores. The pool updates itself.
A cron that pulls live and final scores
A scheduled job, a cron, runs on an interval and pulls live and final scores from a free public sports API. It feeds those results to the scoring engine, which re-grades everyone automatically. Games finish, standings move, and no human touches anything.
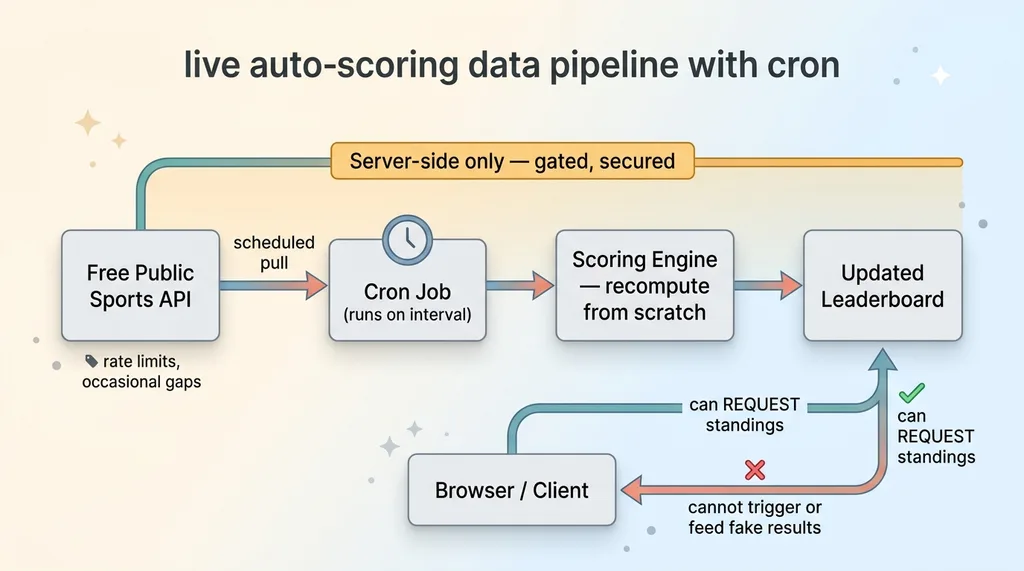 Live auto-scoring data pipeline with cron
Live auto-scoring data pipeline with cron
That is the difference between an app that feels like a product and a spreadsheet someone has to babysit. For three weeks of a tournament, "I have to manually update this" would have killed it by day two.
Auto-grading, gated and secured server-side
The auto-scoring runs entirely server-side and is gated so a client can't trigger it, tamper with it, or feed it fake results. The browser can request the standings. It cannot tell the system what the standings should be.
Now the honest limits. A free public API has rate limits and occasional gaps. Sometimes a score is delayed. Once in a while a number is wrong before it gets corrected.
This is exactly why the recompute design matters so much. When the API corrects a score later, I do nothing. The next recompute reads the corrected value and fixes the standings on its own. The fragile parts of the data pipeline are absorbed by the robust part of the engine.
For a family game, fully unattended auto-scoring is the right call. The stakes are bragging rights. In a higher-stakes system where money or compliance is on the line, I draw the line differently, and that's where I draw the line on letting code run unattended. The rule is simple: automate the deterministic parts fully, and put a human in front of anything where being wrong costs real money. A prediction pool clears that bar easily. Your billing system might not.
The 3D trophy, and why polish is now cheap
The detail that makes people forget this was built in a weekend is the leaderboard. There's a 3D trophy that spins, a mobile-first interface that actually looks finished, and responsive design that holds up whether you open it on a phone or a laptop.
 What AI changed vs what stayed the human's job
What AI changed vs what stayed the human's job
None of that was the hard part. That's the whole point.
For most of my career, the things on that list were exactly what signaled "serious budget, serious timeline." Custom authentication. Live external data. Polished 3D rendering. A responsive interface that doesn't break on someone's old phone. Each of those used to be a line item with weeks attached.
Now they're a weekend, for one person who knows the stack. A big reason is that I'm not starting from zero each time. I build on the same five primitives I use on everything, so auth, data, scheduling, and the deployment pipeline are solved problems I assemble rather than invent.
And yes, the AI wrote most of the actual typing. The boilerplate, the component scaffolding, the glue code, a lot of that came from prompting rather than hand-writing.
But the model did not decide to recompute scores from scratch instead of incrementing. It did not decide passwordless was the right identity model, or that auto-scoring had to be gated server-side. Those judgments were the job. The typing was just labor, and labor got cheap.
That distinction is the answer to the buyer doubt. The hard part was never the code volume. It was knowing what to build and how to keep it correct. AI collapsed the first and changed nothing about the second.
What a weekend project tells you about your roadmap
Here's why a family game is relevant to your business. If a complete, live-updating, polished consumer app ships over a single weekend by one person, then the internal estimate of "six months and a team" for your customer-facing tool deserves a hard second look.
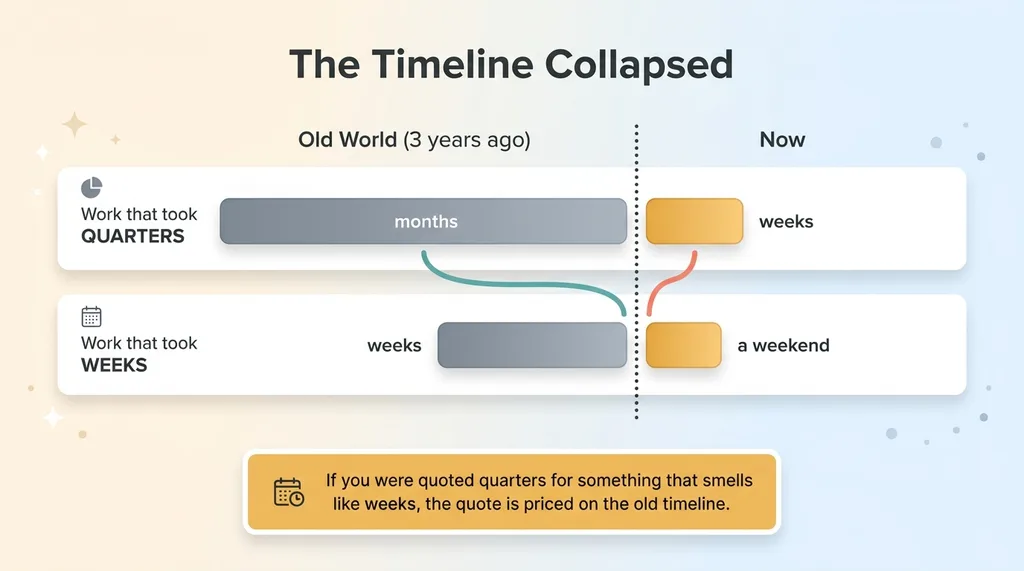 The collapsing software timeline
The collapsing software timeline
I want to be honest about the difference. This was small-scope. A family pool doesn't carry the weight your production system does. Real businesses have compliance requirements, scale demands, edge cases, security audits, and the kind of failure modes where being wrong actually costs money. That weight is real and I'm not waving it away.
But the order-of-magnitude shift is also real. The work that used to take quarters now takes weeks, and the work that used to take weeks now takes a weekend. The weight didn't disappear. It just stopped being the dominant cost. I wrote more about that recalibration in the new timeline for custom software.
So if you've been quoted quarters for something that smells like it should take weeks, the quote might be priced on the old timeline. The team estimating it learned to build in a world that no longer exists.
I'm not saying every project is a weekend. I'm saying the gap between your assumption and reality is probably wide enough to matter to your budget and your roadmap.
If you've been sitting on a build because the timeline felt impossible, tell me what you're trying to build. I'll give you a straight answer on whether it's a weekend, a few weeks, or genuinely a quarter. No pitch attached.
Thinking about AI for your business?
If this resonated, let's have a conversation. I do free 30-minute discovery calls where we look at your operations and find the places where AI could actually move the needle, not the places where it just sounds impressive in a board meeting.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call