AI Development Velocity Proof: 1,900 Commits in a Quarter
AI development velocity proof: 1,900 commits, 31 new products, 49 repos, one operator in 90 days across unrelated industries. The full methodology, audited.
By Mike Hodgen
The Number That Sounds Like a Lie
Roughly 1,900 commits. Across 49 active repositories. Thirty-one brand-new products built from zero to live. One operator. About 90 days.
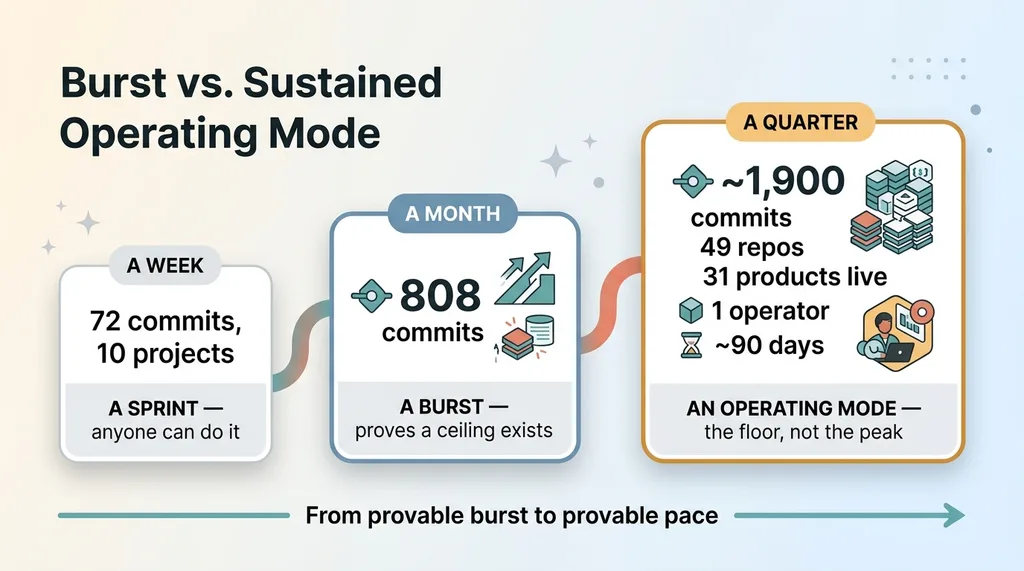 Burst vs. Sustained Operating Mode (Week vs. Month vs. Quarter)
Burst vs. Sustained Operating Mode (Week vs. Month vs. Quarter)
I know how that reads. It reads like a vanity metric, or a guy cherry-picking his best stretch and pretending it's the norm. That was my reaction too when I tallied it up at the end of the quarter. The instinct is to assume I'm padding the number with one-line fixes and counting toy scripts as "products."
So let me set the bar honestly. A few months back I wrote about 808 commits in 30 days. That was a burst, a single intense month that proved a ceiling exists. A burst doesn't prove much. Anyone can sprint for a week. I've documented what one week of AI-first building looks like, and a week is still a sprint.
A quarter is different. A quarter is the thing you can't fake with adrenaline. A week of high output proves a burst. A quarter proves an operating mode. That's the whole point of this post, not the headline number, but whether the output holds up when you sustain it across 90 days and multiple unrelated domains.
This is the ai development velocity proof I actually care about: not the peak, the floor. The pace I can hold without burning out or shipping garbage.
But the number is only worth anything if it's falsifiable. So I'm not going to ask you to take 1,900 on faith. I'm going to show you the methodology behind it, the failures I'd rather not mention, and the exact places where my own math gets soft. If I'm wrong, you should be able to see where.
Why a Commit Count Alone Means Nothing
Commits are an activity metric, not an outcome
Here's the uncomfortable truth: I distrust raw commit counts as much as you do.
A commit can be a full feature with tests and deployment config. Or it can be fixing a typo in a comment. Git treats them identically. If I wanted to inflate the number, I could break every change into ten tiny commits and quadruple the count by lunch.
So a commit count is an activity metric. It measures motion, not progress. Anyone selling you on their commit count is selling you on how busy they look, which is exactly the wrong thing to measure.
What I count instead
What I actually count is shipped, working outcomes. Thirty-one products that went from nothing to live in the quarter.
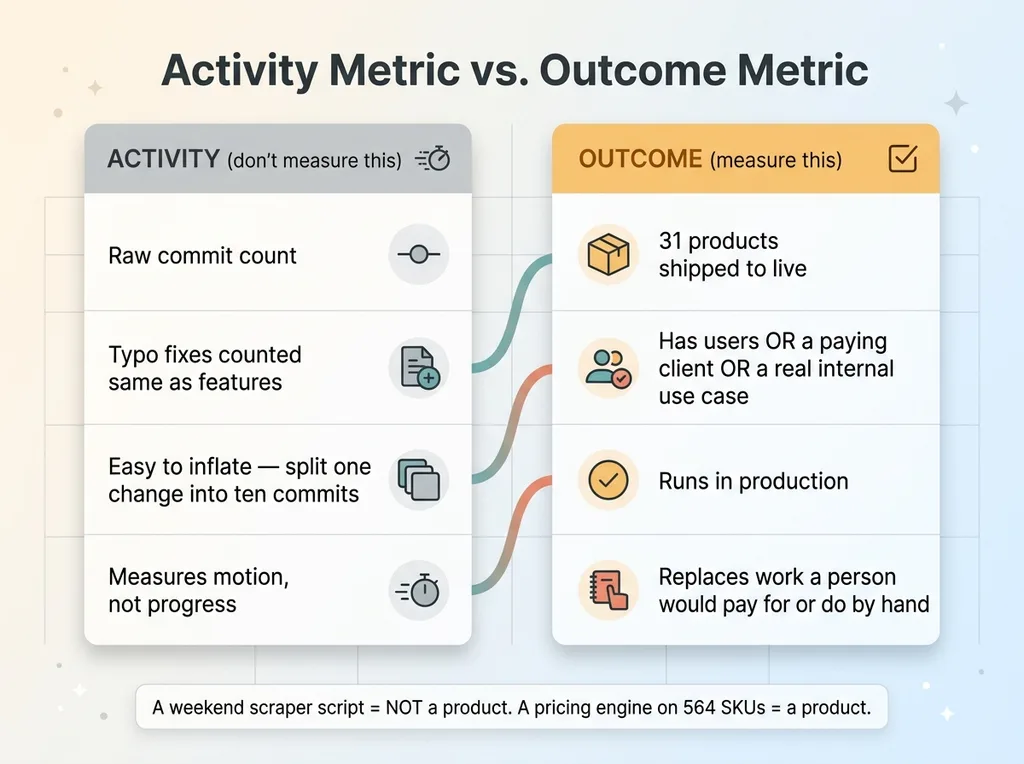 Activity Metric vs. Outcome Metric (what to count)
Activity Metric vs. Outcome Metric (what to count)
And I need to define "product" tightly, or the number inflates on its own. A product here means a real, deployable system, it has users, or a paying client behind it, or a concrete use case I'm running in my own operation. It runs in production. It does something a person would otherwise pay for or do by hand.
A weekend script that scrapes one webpage is not a product. A pricing engine running on 564 SKUs is. A consumer mobile app with a real user is. A content pipeline producing live, ranking articles is.
This is AI output measurement the way it should work: outcomes you can point at, not activity you can pad. The commit count is just the texture underneath. The 31 products are the thing I'd defend in a deposition.
If you only remember one filter from this piece, make it this one. When someone shows you their AI velocity, ask what shipped and who uses it. The number after that question is the only one worth anything.
Breadth Is the Real Proof, Not Volume
Unrelated industries in a single quarter
Volume is easy to fake. Grind one codebase hard enough and you'll rack up commits. A single large app can absorb a thousand commits without proving you can do anything except work on that one app.
Breadth is the part that can't be faked.
In this quarter I was operating as one person running multiple unrelated ventures and client systems simultaneously. The domains had nothing to do with each other. A regulated health context with real privacy constraints. Financial and quant systems where a wrong number isn't a bug, it's a loss. Ecommerce operations for my own DTC fashion brand. Manufacturing tooling for a custom production client. Consumer mobile apps. Professional services content at scale.
Each of those lives in a different world.
Why breadth is harder to fake than volume
Switching domains forces real re-learning. You can't copy-paste your way across them.
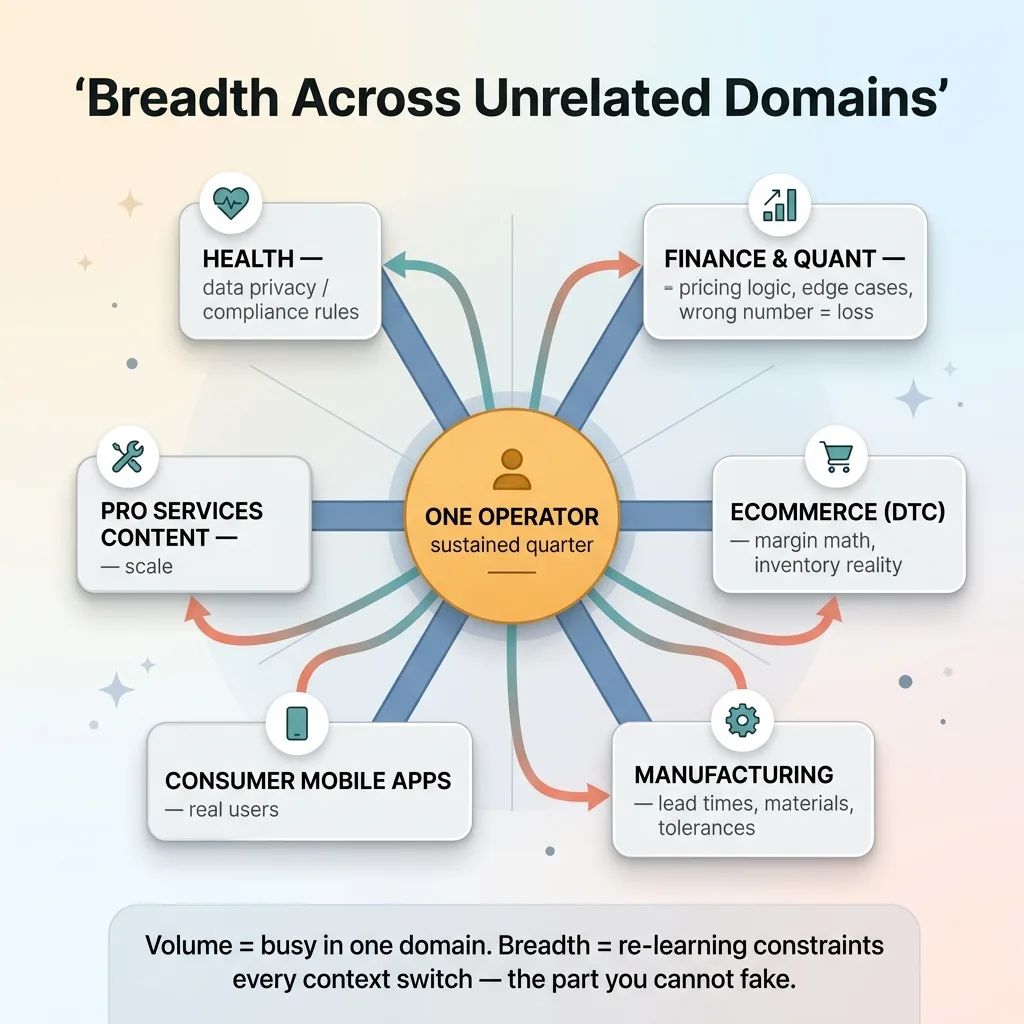 Breadth Across Unrelated Domains
Breadth Across Unrelated Domains
The health context means data privacy rules that will get you in genuine trouble if you ignore them. The financial systems mean pricing logic and edge cases where "close enough" fails. The manufacturing tooling means physical constraints, lead times, materials, tolerances, that no amount of clever code makes disappear. Ecommerce means margin math and inventory reality.
A copy-paste grinder hits a wall the second the constraints change. They've optimized for one shape of problem. Move them to a regulated domain and they ship something that violates compliance, because they never had to learn it.
Sustaining output across genuinely unrelated domains in a single quarter means I re-learned the constraints every time I switched contexts. That's the part that's expensive. That's the part a skeptic actually needs to believe, because it's the part you can't fake by being fast at one thing.
This is why I lead with breadth, not volume, when I talk about sustained AI productivity. Volume tells you someone was busy. Breadth tells you they can hold the operating mode across whatever your business actually requires, which is rarely one tidy domain.
The Hours-Saved Methodology (And Where It's Soft)
How I estimate time saved
The headline figure I quote is 3,000+ hours saved annually. Here's the math behind it, because a number without math is just a wish.
The logic is simple. Take a task. Measure the baseline manual time. Multiply by frequency. Sum across tasks.
Product creation is the cleanest example. In my DTC brand, taking a concept from idea to live product used to take 3 to 4 hours, design, copy, SEO, listing, the whole chain. With my pipeline it takes about 20 minutes. Call it a 3-hour saving per product. Multiply that across the volume of products I run, and one pipeline alone accounts for a big chunk of the total.
Do that across content (313 articles managed through an AI-assisted SEO process), pricing (564 SKUs dynamically priced instead of by hand), customer service, and the rest of the 29 automation modes in production. Sum the savings. You land north of 3,000 hours a year.
I keep the receipts in a deliverables log that proves value, because an estimate you can't audit is a story, not a number.
Where the estimate gets fuzzy
Now the honest part. The estimate is soft in three specific ways.
First, AI introduces new work that the baseline didn't have. Review, debugging, prompt iteration. The 20-minute product isn't 20 minutes of pure gain, some of those 3 saved hours got eaten by setup and oversight elsewhere.
Second, some of these tasks I wouldn't have done at all manually. I'd never hand-write 313 SEO articles. So calling that time "saved" is generous, I didn't save it, I made the work possible at all.
Third, the baselines are self-reported, and self-reporting has a bias toward making the before look slow. I try to be conservative. I'm sure I'm not perfectly calibrated.
The number is real. It's also fuzzy at the edges. Both things are true, and the AI hours saved methodology is more believable when I say so out loud.
How One Person Sustains This (The Operating Model)
The natural objection: this sounds superhuman, so it's probably exaggerated. It isn't superhuman. It's a system. Here's how a one person AI operation actually holds this pace.
Multi-LLM division of labor
I don't use one model for everything. I run a multi-LLM architecture where different jobs go to different models. Claude handles content and reasoning. Gemini handles image generation. I chain them together with custom logic for cost efficiency, so the expensive model only does the work that needs it.
This matters because the wrong tool for a job is where time and money leak. Routing each task to the right model is most of the efficiency.
Quality control that rejects its own work
The thing that lets me sleep is self-auditing. My systems are built to catch bad output before I see it.
Generated content gets checked against rules before it's allowed through. Pricing decisions get validated against guardrails. If output fails the audit, it gets rejected and retried, not shipped. The 22,000+ lines of custom Python in my toolkit are largely this, the boring checking layer that means I'm reviewing exceptions, not everything.
A system that rejects its own work is how one person reviews the output of 29 automation modes without becoming the bottleneck.
Reusable scaffolding across projects
This is the real secret, and it's unglamorous. Each new product doesn't start from zero.
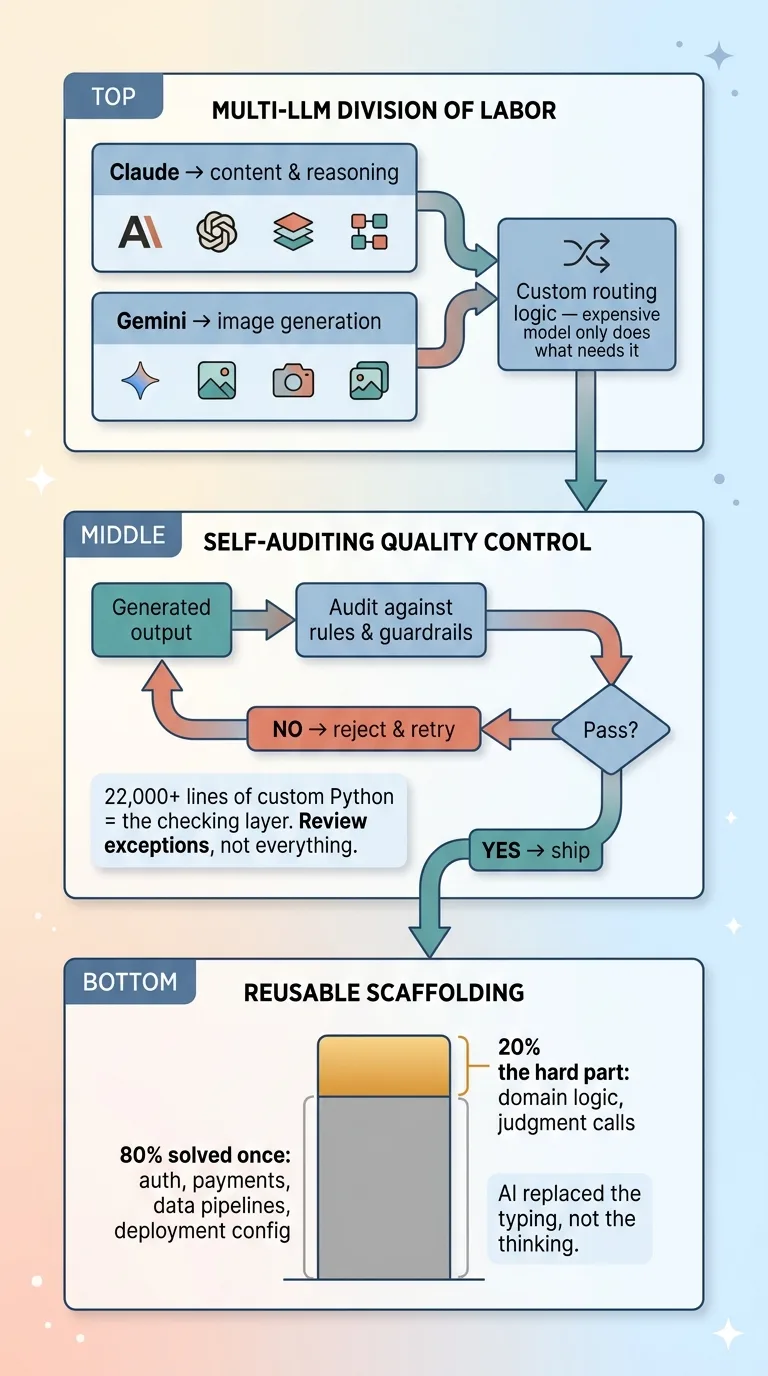 The Operating Model, How One Person Sustains the Pace
The Operating Model, How One Person Sustains the Pace
Auth, payments, data pipelines, deployment config, that's roughly the same 80% across every project. I solved it once and I reuse it. When I start product number 32, the plumbing already exists. I'm not rebuilding login screens.
So velocity isn't typing faster. It's that the boilerplate 80% is solved once and reused, which leaves my actual time for the hard 20%, the pricing logic, the domain constraints, the judgment calls a model can't make. AI replaced the typing. It didn't replace the thinking. The thinking is still all me, and it's still the slow part. The scaffolding just stops the slow part from drowning in the fast part.
The Self-Audit: What Didn't Ship and What Broke
If I only show you the wins, this is a flex, not a proof. So here's the audit.
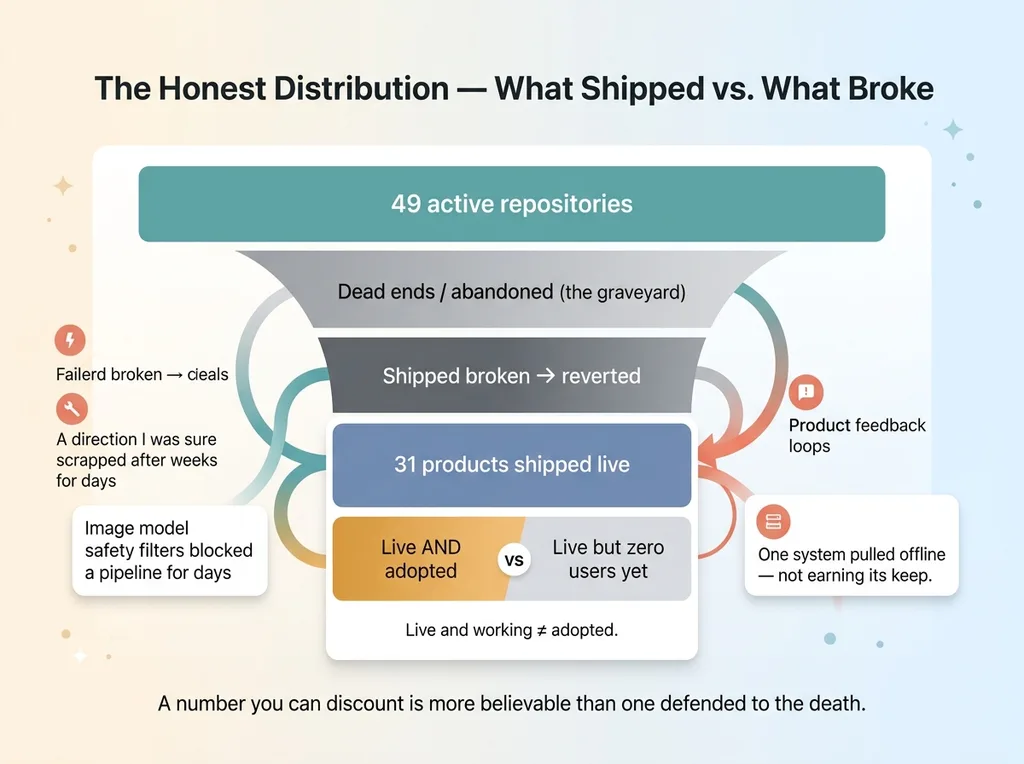 The Honest Distribution, What Shipped vs. What Broke
The Honest Distribution, What Shipped vs. What Broke
Not every one of the 49 repos became a product. Many were dead ends. I started things, learned they wouldn't work, and abandoned them. That's where a good chunk of those repos live, in the graveyard, not in production.
Of the things that did get built, some shipped broken and got reverted. I pushed a change, it failed in a way the audit didn't catch, and I rolled it back. That happened more than once.
Specific categories of failure from this quarter: safety filters on an image model blocked an entire generation pipeline for days until I worked around them. One approach to a problem I was sure about simply didn't pan out, and I scrapped weeks of direction. One system I'd built got pulled offline because it wasn't earning its keep.
And of the 31 products that shipped? Some have zero users. Live and working is not the same as adopted. A few of them are real systems that nobody has needed yet.
That's the honest distribution. Plenty of motion turned into nothing. A number you're willing to discount is more believable than one you defend to the death, so discount mine accordingly. The 31 that shipped are real. The path to them was littered with the ones that didn't.
What a Sustained Operating Mode Means for Your Business
Here's the takeaway if you're running a company and wondering why any of this matters to you.
Most AI initiatives stall after the pilot. A vendor demos something impressive, everyone nods, and six months later it's a Slack channel nobody opens. The demo was a burst. There was no operating mode behind it.
The difference between 808 commits in a month and 1,900 across a quarter is the difference between a vendor who can demo once and an operator who can sustain output across your whole business over quarters, not weeks. That's the thing I'm actually proving here. Not that I'm fast, that the pace holds.
What I bring to a business is the reusable scaffolding and the operating model, not a slide deck. The auth, the pipelines, the self-auditing quality control, the multi-model routing, that 80% is already solved, so your projects don't start from zero either. I write more about why that matters in I build it, not just advise on it. The short version: I'd rather show you a working system than a recommendation.
Imagine a quarter of this aimed at one business, yours. Not 31 products across six industries, but that same sustained pace focused on the handful of things in your operation that actually cost you time and money.
That's a conversation worth having.
Thinking about AI for your business?
If this resonated, let's talk. I do free 30-minute discovery calls where we look at your actual operations and find where AI could genuinely move the needle, not where it sounds impressive.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call