How to Work With AI Coding Agents: A Day Inside
Curious how to work with AI coding agents in practice? Here's the actual discipline behind directing parallel agents to ship real software, no theory.
By Mike Hodgen
What 'I Use AI Agents' Actually Hides
Everyone says they use AI agents now. It's the new "we're data-driven." The phrase tells you nothing.
Here's the problem if you're a CEO trying to hire help or evaluate a vendor: you can't tell craft from chaos by listening. The person who's built a real methodology and the person throwing prompts at a model and hoping both say the same words. Both demo something that looks impressive for ten minutes.
The difference shows up later. One ships systems that hold up under load. The other ships a pile of half-finished branches, merge conflicts, and confident-sounding code that breaks the moment a real customer touches it.
Most people directing agents right now are gambling with glorified autocomplete. They're not orchestrating anything. They're rolling dice faster.
I want to show you the actual operating rhythm. Not theory, not a sanitized demo built to make the tool look good. This is how I actually work with AI coding agents across my own projects, my DTC fashion brand, my internal tools, and client systems I've shipped.
There are four rules I follow. They're not complicated. But they're the difference between AI work that ships and AI work that joins the pile of failed projects nobody talks about at the board meeting.
If you've been burned by a vendor who promised autonomous AI and delivered expensive chaos, this is the part they skipped. The discipline. Not the model, the method.
Let me walk you through a real day.
Rule One: Parallelize Research, Serialize Coupled Code
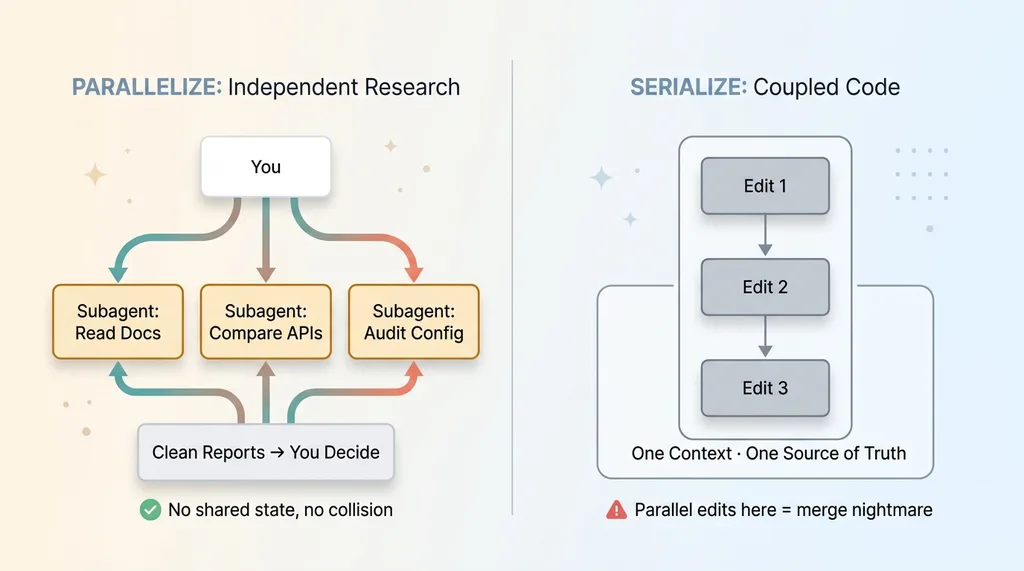
The single most important distinction in a multi agent workflow is this: some work can run side by side, and some work absolutely cannot. Mixing them up is where amateurs lose entire afternoons.
 Parallelize Research vs Serialize Coupled Code
Parallelize Research vs Serialize Coupled Code
Independent tasks run side by side
Research is independent by nature. If I need to investigate three different payment APIs, summarize a library's documentation, and audit a config file, none of those tasks touch each other. They can't corrupt each other's work because there's no shared state. There's nothing to collide.
So I spin up three subagents and let them run at once. One reads the docs. One compares the API options. One audits the config. Twenty minutes later I have three clean reports and I make the call. That's parallel AI agents doing what they're actually good at: gathering, not editing.
Coupled edits stay in one context
Code is different. The moment two edits touch the same files or share state, parallelizing them is a recipe for garbage. Agent A refactors a function assuming one structure. Agent B refactors the same module assuming another. Now you have two branches that each work alone and break together.
When I refactor a coupled module, that work stays in a single serial thread. One context, one set of assumptions, one source of truth. No exceptions.
The mistake I see constantly is people parallelizing everything because it feels productive. More agents, more speed, right? Wrong. You get inconsistent assumptions and a merge nightmare that costs more time than working serially would have.
This rhythm scales when you respect it. I shipped 808 commits in 30 days running exactly this discipline. That volume isn't recklessness. It's knowing what to parallelize and what to keep in one hand.
Rule Two: Auto-Enhance the Vague Idea Before Any Agent Runs
A vague instruction produces vague work. Every time. If you hand an agent "add a returns flow," you'll get something that technically exists and solves none of your actual problem.
Before I let any agent write a line of code, I turn the one-line idea into real requirements.
From one sentence to real requirements
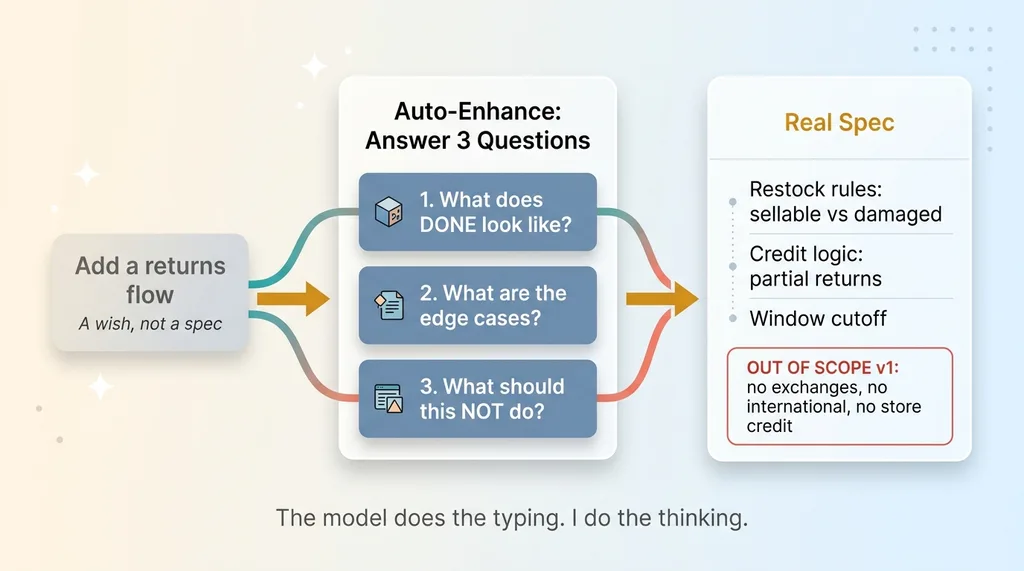
"Add a returns flow" is not a spec. It's a wish. So I sit with it first and answer three questions. What does done actually look like? What are the edge cases? And what should this explicitly NOT do?
 From Vague Idea to Real Requirements
From Vague Idea to Real Requirements
For that returns flow, the real spec becomes: restock rules for sellable versus damaged items, credit logic that handles partial returns, a window cutoff, and an explicit out-of-scope list (no exchanges, no international returns, no store credit conversions in v1).
Now the agent has a target. The work it produces is something I can actually use instead of something I have to throw away and redo.
Architect before you execute
I treat the ideate-then-architect step as a deliberate gate. Nothing executes until the requirements and the rough architecture exist. This is where the human thinking lives.
The model does the typing. I do the thinking. That distinction is the whole game. AI replaced the keyboard work, the boilerplate, the syntax I used to grind through. It did not replace the judgment about what should be built and why.
This one step separates reliable output from expensive rework. When I skip it because I'm in a hurry, I pay for it within the hour. Directing AI agents well isn't about better prompts. It's about knowing what you actually want before you ask.
Rule Three: Gate Every Irreversible Change
Speed without a kill-switch is a liability. This is the discipline that earns trust, especially from a CEO who's seen a vendor move fast and break something that mattered.
What counts as irreversible
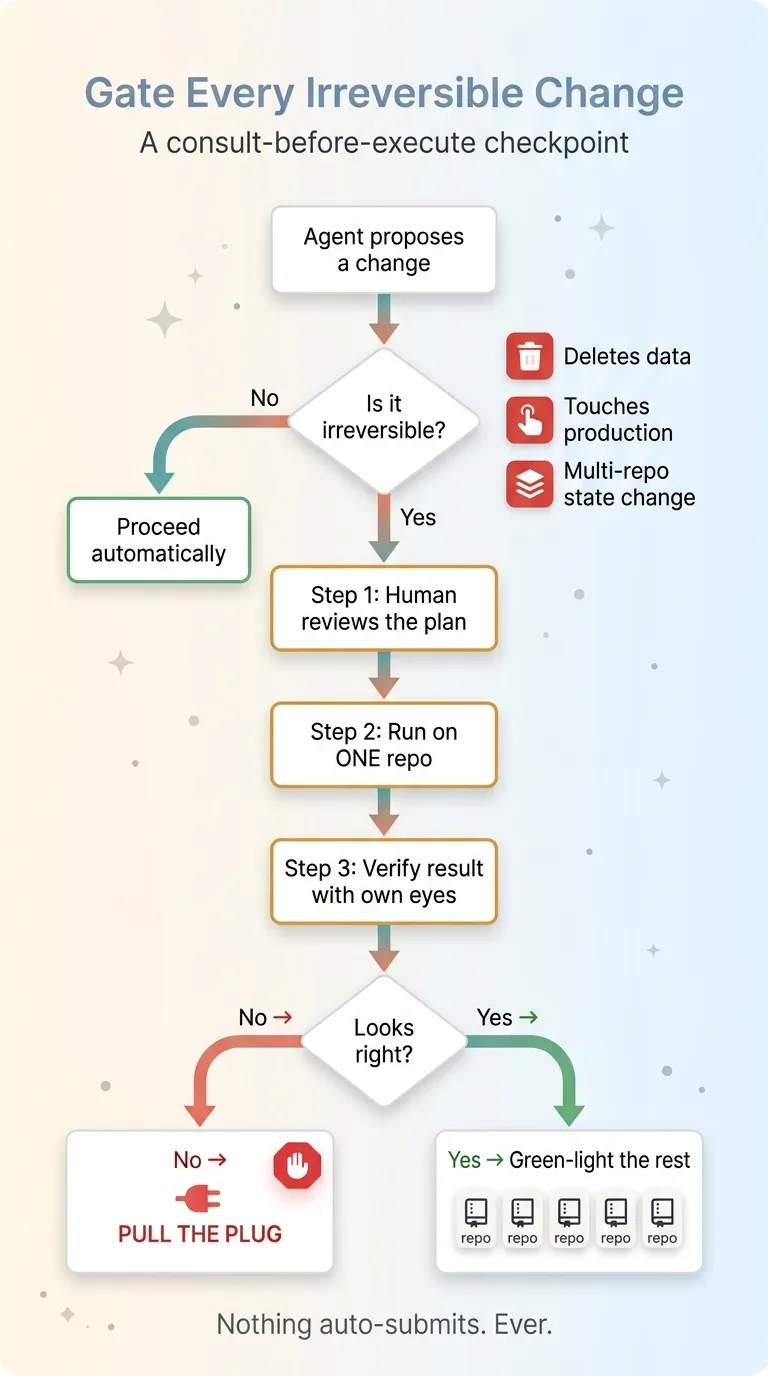
I draw a hard line around three things. Anything that deletes data. Anything that touches production. And anything that changes state across multiple repos at once. Those are irreversible. You can't quietly undo them, and a mistake there isn't a bug, it's an incident.
For everything in that category, the agent proposes and I approve. Nothing auto-submits. Ever. Every system I ship stops for a human at exactly these checkpoints, by design, not by accident.
The consult-before-execute checkpoint
Here's a real example. Say a change needs to update a shared schema across five projects. An autonomous agent would happily run all five and report a clean success. Until project three fails halfway and now your schema is inconsistent across your whole stack.
 Gating Irreversible Changes (Consult-Before-Execute Checkpoint)
Gating Irreversible Changes (Consult-Before-Execute Checkpoint)
So I don't do that. I review the plan. I run it on one repo. I verify the result with my own eyes. Then I green-light the rest. That's where I pull the plug if something looks off, before the blast radius gets big.
This is the difference between an operator and someone who lets autonomous AI run wild and reports wins it never earned. The agents that brag about full autonomy are the ones I trust least. Real orchestration means knowing exactly where to put your hand on the wheel.
Rule Four: Spawn Subagents Only for Genuinely Independent Work
Subagents are not magic. They're a tool for one specific job: parallel work that's genuinely independent. That's it. The whole skill of AI agent orchestration in practice comes down to recognizing when work is actually independent and when it just looks that way.
 Fan-Out Research vs Fan-Out Editing (When to Spawn Subagents)
Fan-Out Research vs Fan-Out Editing (When to Spawn Subagents)
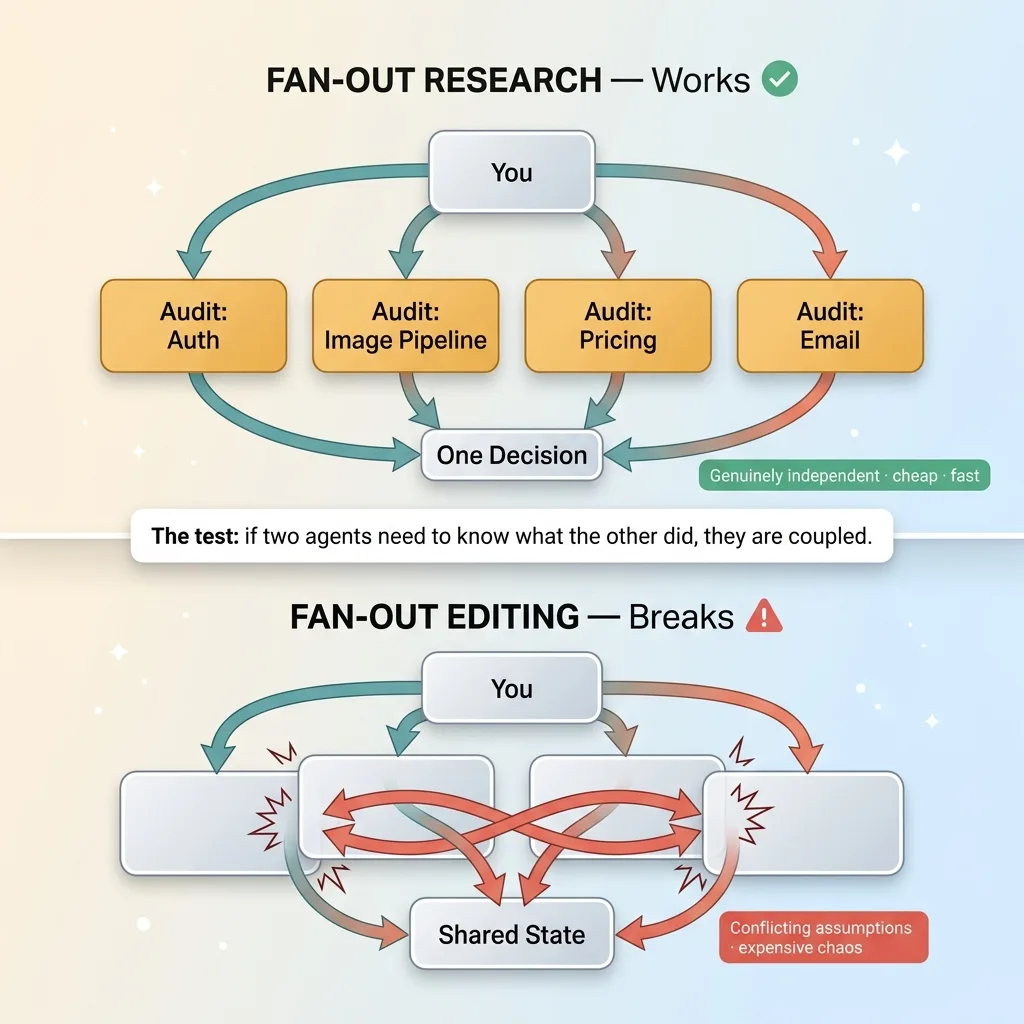
The test is simple. If two subagents need to know what the other one did, they shouldn't be separate agents. They're coupled. Forcing them apart just means you reassemble two incompatible halves later.
Here's where subagents earn their keep. Say I need to audit four unrelated parts of a codebase: the auth layer, the image pipeline, the pricing logic, and the email templates. None of those audits depend on the others. So I dispatch four subagents at once, each scoped to one area, and collect their findings into a single decision I make.
That's fan-out research. It's cheap, it's fast, and the parallel structure matches the work.
Fan-out editing is the opposite. The moment subagents start writing code that touches shared state, you've created expensive chaos. Each one builds on assumptions the others don't share. You spend more time reconciling their work than you saved by splitting it.
So the skill people miss isn't spawning more agents. It's knowing when not to. A senior operator running one serial context will beat a junior running ten parallel agents on coupled work every single time.
When I see someone bragging about how many agents they run at once, I don't hear sophistication. I hear someone who hasn't been burned yet. The number of agents is not the metric. The fit between the structure and the work is the metric.
What a Real Day Looks Like Start to Finish
Let me put it together with a representative session from my own projects.
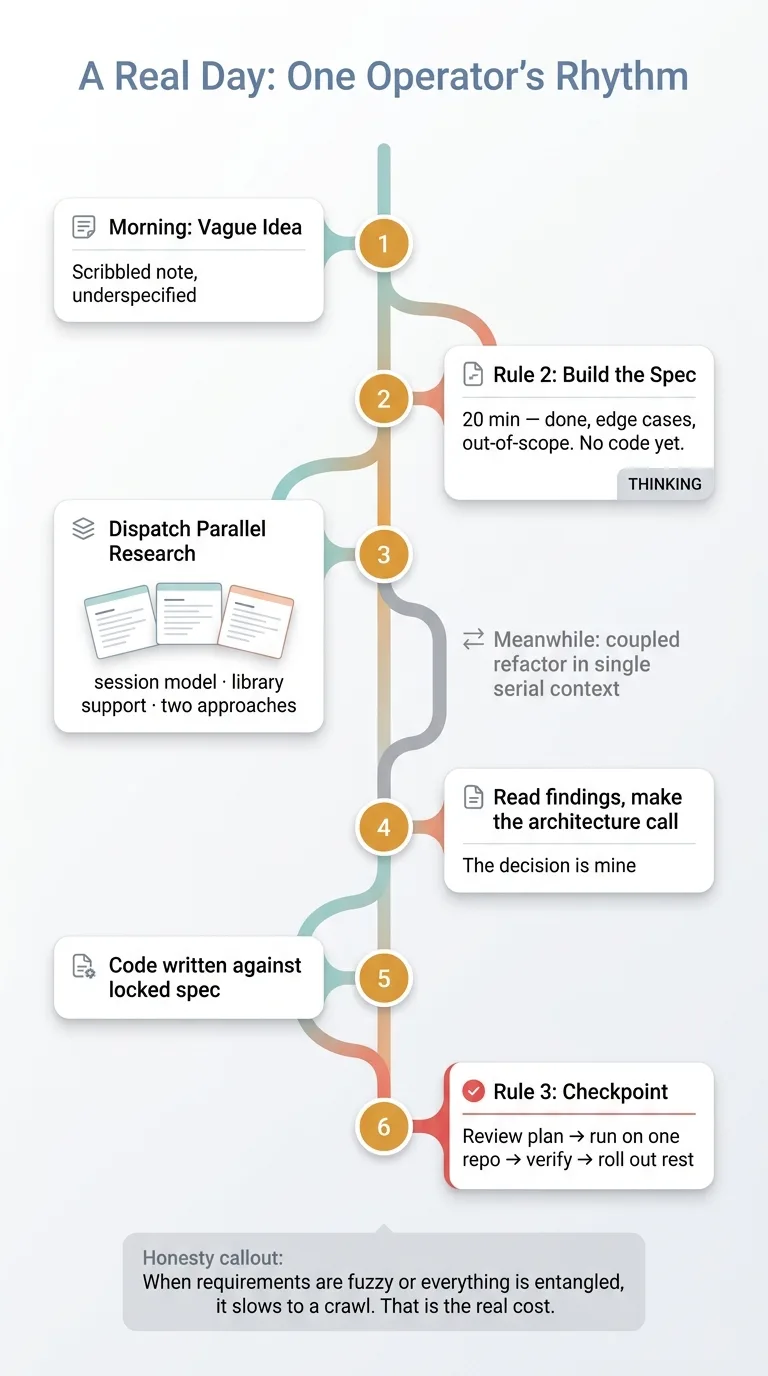 A Real Day: The Repeatable Operating Rhythm
A Real Day: The Repeatable Operating Rhythm
Morning starts with a vague idea. Usually mine, scribbled the night before. "We should let customers save items across devices" or something equally underspecified. First move, Rule Two. I spend twenty minutes turning that into real requirements: what done looks like, the edge cases, the explicit out-of-scope list. No code yet.
Once the spec exists, I dispatch parallel research subagents on the independent questions. How does the current session model work? What does the library we already use support? What are two competing approaches and their tradeoffs? Three agents, three clean reports, none of them touching the others.
While those run, I'm not sitting idle. I've got a coupled refactor open in a single serial context, the kind of work that has to stay in one hand. So I'm reviewing that thread while the research fans out in the background. Two modes of work, neither stepping on the other.
The findings come back. I read them, weigh the tradeoffs, and make the architecture call myself. That decision is mine. The agents informed it, they didn't make it. Then the code gets written against the spec I locked in this morning.
Before anything deploys across repos, I hit the Rule Three checkpoint. I review the deploy plan, run it on one project, verify it actually works, then roll out the rest. No auto-submit on the irreversible step.
That's a repeatable rhythm one person runs. Not a chaotic free-for-all with twelve agents fighting each other.
And here's the honest part. When the requirements are genuinely fuzzy and I can't pin them down, or when a change is so entangled that nothing can be parallelized, the whole thing slows to a crawl. I work serially, one careful step at a time, and the speed advantage mostly disappears. That's the real cost, and anyone telling you it never happens is selling you something.
Why the Method Matters More Than the Models
Come back to the doubt I opened with. You can't tell craft from chaos by listening, and everyone uses the same words.
Here's what cuts through it. The models change every few months. Today's frontier model is next quarter's baseline. Anyone can buy access to the exact agents I use. The subscription is the easy part.
What you can't buy off the shelf is the operating rhythm. Parallelize research, serialize coupled edits, gate every irreversible change, architect before you execute. That discipline is the durable part. It worked on last year's models and it'll work on next year's, because it's about judgment, not tooling.
That's the actual craft. And it's why most AI projects fail. The reported failure rate sits around 88 percent, and it's not because the models are bad. It's because nobody applied a method. They threw prompts at a model and hoped, then wondered why production broke.
Hiring someone who has this rhythm is the difference between AI work that ships and AI work that quietly dies in a forgotten branch. I don't just advise on this from a slide deck. I build it, and I run this exact rhythm every day on real systems, my own brand and client work both.
If you've got a project stuck in that 88 percent, or you're trying to figure out who actually knows what they're doing, that's the conversation worth having.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI actually fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call