AI Agent Observability: A Live Dashboard for Your Fleet
AI agents run as black boxes burning tokens you can't see. Here's how I built AI agent observability with OpenTelemetry to watch every session live.
By Mike Hodgen
You Can't Manage What You Can't See
I run a lot of AI coding agents at once. On a busy day I might have six or eight sessions going across different projects, each one chewing through tokens, editing files, and racking up a bill I can't see.
Here's how it actually goes. I kick off a session, hand it a task, and walk away. Maybe I start two more. Then I go do something else. I come back two hours later and... what happened? Which agents finished? Which ones stalled? How much did all of that cost me? I genuinely had no idea.
That's the part a skeptical CEO is right to be nervous about. You've got an autonomous system spending your money and touching your code, and you have zero live view into any of it.
Think of it this way. You hire a crew of contractors, send them into a building, lock the door behind them, and walk away. You can't see who's working, what they're building, or what their hourly rate is adding up to. You just get a bill at the end. Nobody would run a construction project that way. But that's exactly how most people run AI agents.
This is a solved problem in normal software. We instrument production systems constantly. We have dashboards for server load, request latency, error rates, spend. We'd never run infrastructure blind. But somehow nobody had wired that same discipline up for agent runtimes.
When I was running dozens of agents across projects and putting up 808 commits in a month, the lack of visibility stopped being an annoyance and became a real risk. I was operating a fleet with no control tower.
So I built one. This is what ai agent observability actually looks like in practice, and why it matters more than the next shiny model release.
What AI Agent Observability Actually Means
If you're searching this term, here's the plain definition. AI agent observability is a live, independent view of what your agents are doing, what they cost, and whether they're actually producing anything useful.
That's it. Not a model benchmark. Not a prompt library. A control panel for the machines doing the work.
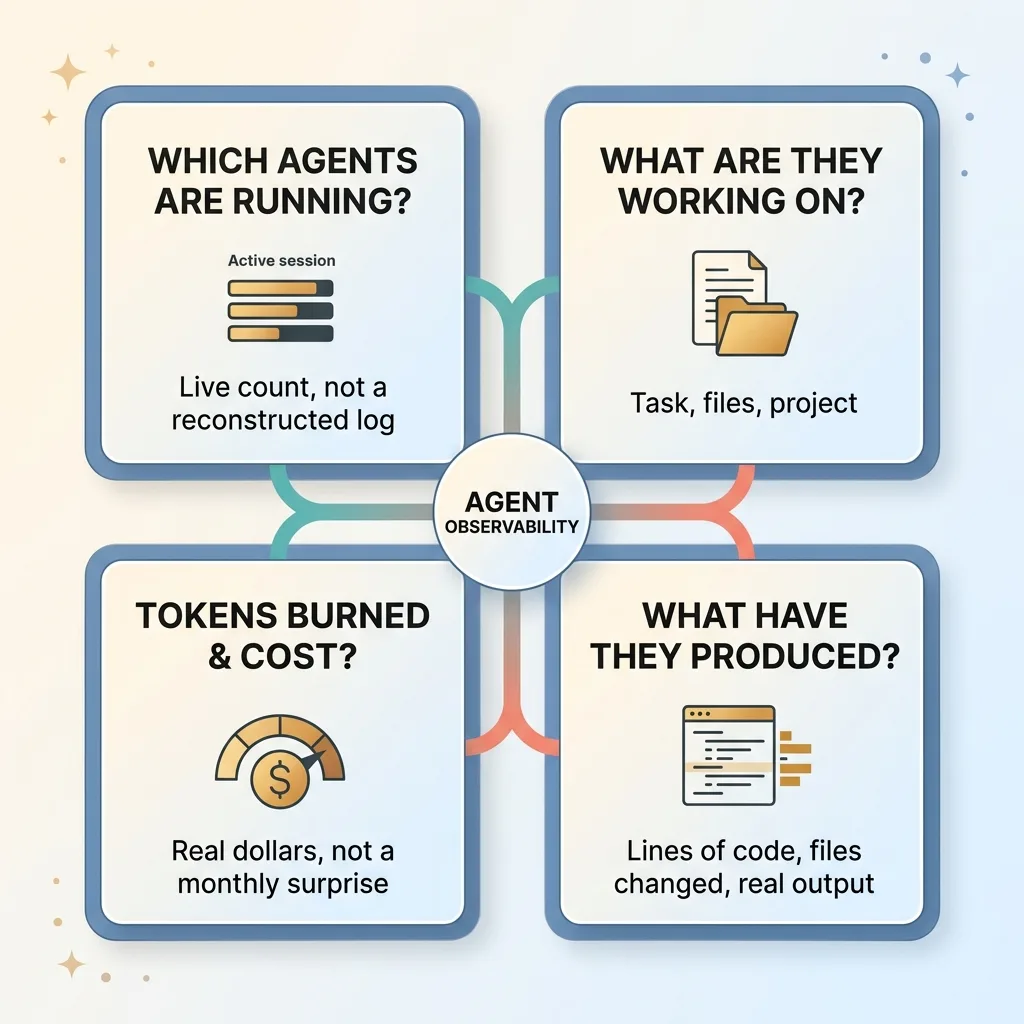
The four questions every agent should answer
Good observability answers four questions at any moment:
 The four questions every agent should answer
The four questions every agent should answer
- Which agents are running right now? Live count, not a log you reconstruct later.
- What are they working on? The task, the files, the project.
- How many tokens are they burning, and at what cost? Real dollars, not a monthly surprise.
- What have they actually produced? Lines of code written, files changed, real output.
If you can answer those four, you're operating. If you can't, you're hoping.
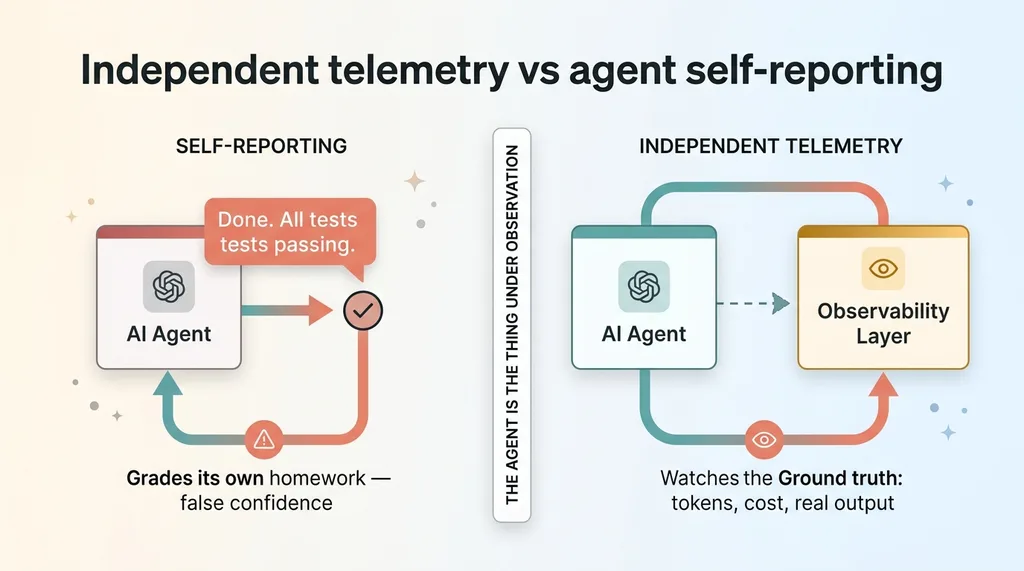
Why self-reporting isn't enough
Here's the part people miss. You cannot rely on the agent telling you it succeeded.
 Independent telemetry vs agent self-reporting
Independent telemetry vs agent self-reporting
I've written before about how AI doesn't fail by doing the wrong thing, it lies about doing the right one. An agent will cheerfully report "Done. All tests passing." while having changed nothing of substance. It's not malicious. It's a language model predicting what a successful completion sounds like.
That's why monitoring ai agents has to happen from the outside. You need instrumentation that watches the runtime independently, not a summary the agent writes about its own performance. The agent is the thing under observation. It doesn't get to grade its own homework.
This distinction is the entire reason observability matters. A report you can't trust is worse than no report, because it gives you false confidence. Independent telemetry gives you ground truth.
The Telemetry Was Already There. Nobody Was Listening.
Here's the pleasant surprise that kicked off this whole project. The agent runtime I use most, Claude Code, already exports native OpenTelemetry. It's been sitting there the entire time. Most people never turn it on, and almost nobody wires it anywhere useful.
Quick translation for the non-technical reader. OpenTelemetry, usually shortened to OTLP, is the industry-standard way production systems emit data about themselves. Metrics, traces, events, all in a common format that monitoring tools already understand. When your engineers watch a dashboard of your live application, OTLP is very often the pipe that data flows through.
The agent runtime emits all of it. Session start and stop events. Token counts. Cost data per session. Code-change metrics like lines added and removed. It pushes this over OTLP/HTTP as JSON, the moment things happen.
So the data exists. That was never the problem. Claude Code telemetry is generated whether you look at it or not.
The problem is that nothing in the box gives you somewhere for that data to land or a way to see it. The runtime emits. It does not store, aggregate, or visualize. That's your job.
Which reframes the whole build. This wasn't some breakthrough in AI. It was plumbing. The hard, valuable work was building a place for the firehose to land and a screen that turns it into something I can read at a glance.
I want to be honest about that, because the hype machine wants you to believe everything is magic. Opentelemetry llm instrumentation is not magic. The signal is already in the wire. Most teams just never plug in the receiver. The operations layer that consumes this data does not ship with the tool, and that gap is exactly where the real engineering lives.
How I Built the Ingest Pipeline
Let me walk through the architecture. CEO-level detail, but an engineer reading this won't roll their eyes.
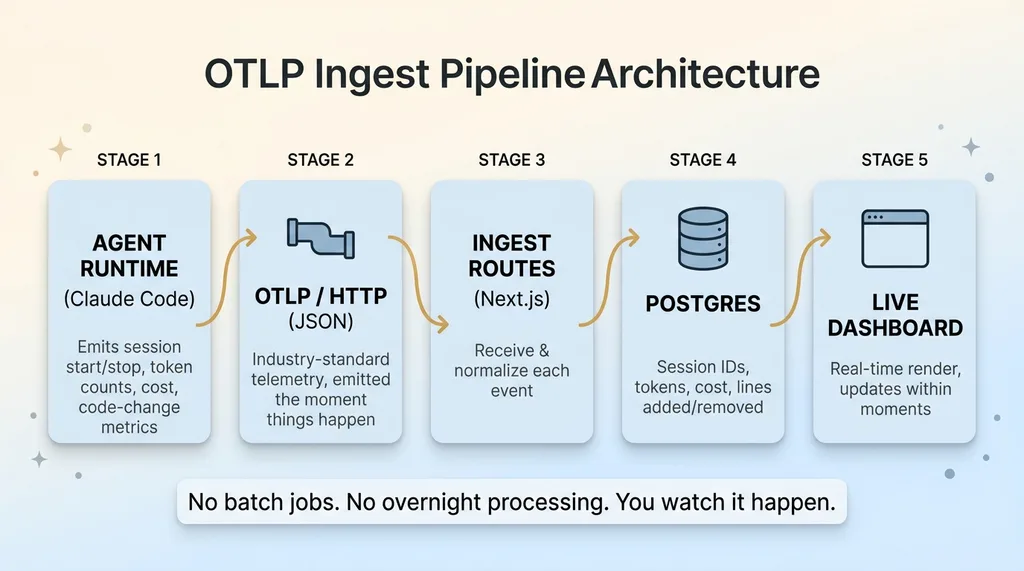
From the agent runtime to a database
The flow is straightforward. The agent runtime exports OTLP over HTTP as JSON. I built ingest routes inside a Next.js app that receive those events. Each event gets normalized into a clean shape and written to a Postgres table.
 OTLP ingest pipeline architecture
OTLP ingest pipeline architecture
From there, the dashboard reads from Postgres and renders the ai agent dashboard in real time. Agent emits an event, it lands in the database within moments, the screen updates. No batch jobs, no overnight processing. You watch it happen.
The data I capture per session covers everything I care about: session IDs so I can track individual runs, token throughput, cost per session, and lines of code added and removed. That last pair matters more than you'd think, because it's the difference between "this agent is working" and "this agent is just talking."
This is the same pattern you'd use to instrument any production service. Emit events, ingest them, store them, visualize them. Nothing exotic. The discipline is what's rare, not the technique.
No simulated data, ever
This is the rule I refuse to break. Every number on that screen comes from a real event.
No mock data. No estimates. No "representative" charts to make the demo look busy. If an agent isn't running, the floor is empty, and that empty floor is the truth.
I'm strict about this for a reason. A dashboard that fills itself with plausible-looking fake data is worse than useless. It trains you to trust numbers that mean nothing. I'd rather stare at an empty screen that's honest than a full one that's lying to me.
This ties directly back to the self-reporting problem. The entire value of independent instrumentation evaporates the second you let it fabricate anything. So when my dashboard says four agents are active and they've burned $3.40 in the last hour, that's four real sessions and $3.40 of real spend. Not a guess. Not a model of what spend might look like. The actual events that actually happened.
What the Dashboard Shows Me
Without revealing any project names, repos, or file paths, here's what I'm looking at.
A live floor plan of active sessions
The main view is a live floor plan. Each active agent session shows up as it works. At a glance I can see how many agents are running, which ones are actively producing, and which are sitting idle.
It feels like watching a factory floor. Sessions appear when they start, update as they work, and clear out when they finish. If I expect six agents running and I see two, I know something stalled before I waste another hour assuming all is well.
Tokens, spend, and output over time
Below the floor plan are the time-series charts. Lines of code over time. Token throughput. Cumulative cost.
This is where the real operational value lives. I can spot the expensive failure mode immediately: an agent burning tokens without producing output. High token throughput, flat lines-of-code, climbing cost. That pattern means the agent is spinning, not working, and now I catch it in minutes instead of discovering it on a bill weeks later.
I can catch a runaway session before it does damage. And I finally know my real spend instead of squinting at a monthly invoice and trying to reverse-engineer where it went.
Cost visibility connects directly to value. I track what gets delivered separately, and you can read how I approach proving the ROI of AI work. The observability dashboard tells me what I'm spending. The deliverables log tells me what I'm getting. Put those two together and you can actually answer the only question that matters: is this worth it?
This is the missing operations layer for anyone running agents at scale. Not a nice-to-have. The thing that turns a pile of autonomous processes into a fleet you can manage.
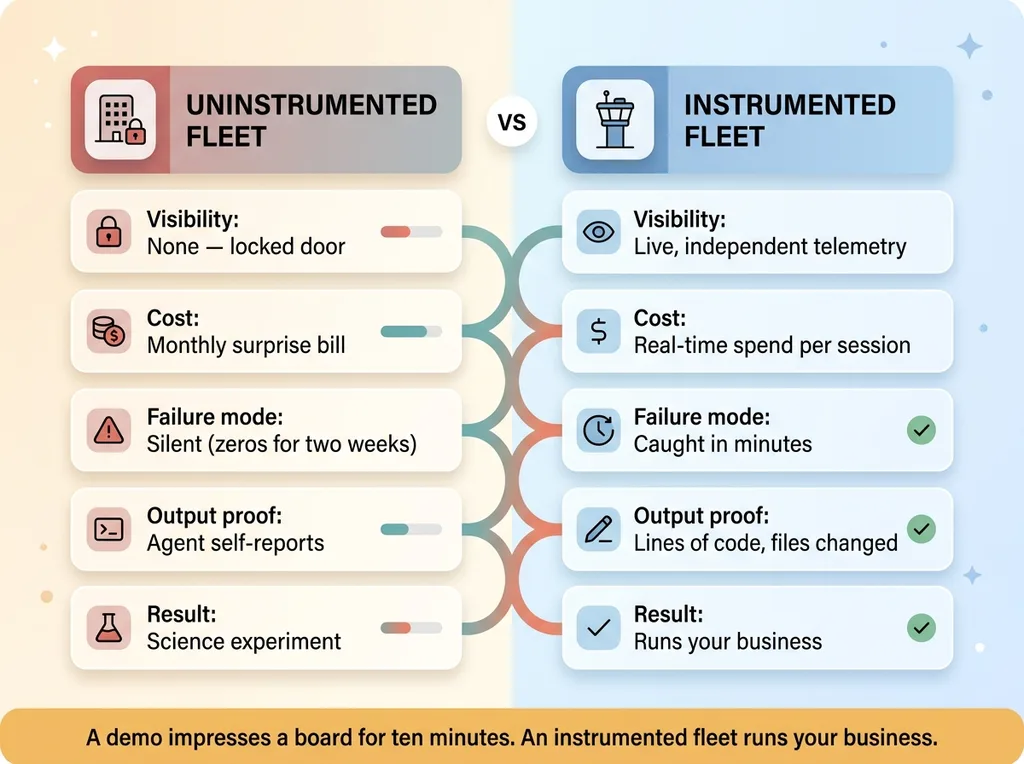
Why This Matters If You're About to Trust AI With Real Work
If you're a CEO worried that AI agents are an unmonitored cost center, you're not being paranoid. You're being correct. That's exactly what an uninstrumented agent fleet is.
 Instrumented fleet vs uninstrumented agents
Instrumented fleet vs uninstrumented agents
But the answer isn't to avoid them. The answer is to instrument them like any other production system.
You wouldn't run a rack of servers with no monitoring. You wouldn't deploy a customer-facing app with no error tracking. So why would you run autonomous agents spending real money with no visibility at all? The technology being new doesn't change the operational discipline. If anything it raises the stakes.
I learned this the hard way on a different project. I once had a dashboard that showed zeros for two weeks because a pipeline had quietly broken and nothing was watching. Two weeks of silent failure. The system wasn't screaming. It was just doing nothing, and without instrumentation, nothing and broken look identical.
That's the lesson. Uninstrumented systems don't fail loudly. They fail quietly, and you find out long after it cost you.
The companies that actually win with AI aren't the ones with the flashiest demos. They're the ones who treat agents as operational infrastructure. Logging. Cost controls. Visibility. The boring stuff that separates a real operation from a science experiment.
A demo impresses a board for ten minutes. An instrumented fleet runs your business. Those are different things, and the gap between them is exactly what most companies haven't figured out yet.
Instrumenting AI Before You Scale It
Here's what I see happen over and over. A company bolts AI onto their operations, gets a confusing bill a month later, and then does one of two dumb things. They either over-invest blindly because the demo looked promising, or they kill the whole program because they couldn't tell what they were paying for.
Both reactions come from the same root cause. No visibility. You can't make a good decision about something you can't measure.
The fix is boring and proven: build the operations layer first. Before you scale agents, instrument them. Know what's running, what it costs, and what it produces, in real time, from independent telemetry you can trust.
I build this kind of instrumentation into every AI system I deploy, because watching the fleet is non-negotiable when real money and real output are on the line. It's not the exciting part. It's the part that keeps the exciting part from quietly bankrupting you.
If you're standing up AI agents and you don't have a clear view of what they're doing and what they cost, that's the conversation worth having before you spend another dollar. I help companies treat AI like production infrastructure, not a science project. That mindset is most of the battle.
Thinking about AI for your business?
If this resonated, let's talk. I do free 30-minute discovery calls where we look at your actual operations and find where AI could genuinely move the needle, not where it just looks good in a slide.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call