AI Code Security Debt: The Tax on Fast Builds
AI code security debt is real and predictable. Here are the four failure patterns that show up in every fast build, and how I pay them down with templates.
By Mike Hodgen
Speed Is Real. So Is the Bill.
I shipped a working product last week. Concept on Monday, live by Friday. That's not a brag, it's just what the job looks like now. If you've been told that AI-assisted development can take an idea to production in days instead of months, you've been told the truth.
Here's the part the skeptic in your engineering org is also right about: fast builds carry debt. I'm not going to argue with that. I've lived it. When you move at the speed AI lets you move, you accumulate AI code security debt, the specific class of shortcuts that creep in when you're optimizing for "ship it" over "harden it."
So we agree on the existence of the bill. The disagreement is about its nature.
The common story is that vibe coding produces random chaos. Unpredictable messes. A different landmine in every project. If that were true, fast builds would be uninsurable, and the cautious buyer would be right to slow everything down.
But that's not what I've found. I spent real time auditing a stack of fast-built projects, a portfolio of solo-built apps, and the debt wasn't random at all. It was the same handful of failures, over and over, in roughly the same places. Predictable enough that I could write a checklist.
And predictable debt is payable debt.
This essay names the four recurring failure patterns I see in AI-assisted builds, and the discipline that pays them down without slowing you back to a crawl. If you've shipped fast and you're wondering what's hiding inside, this is the map.
What "AI Code Security Debt" Actually Means
Let me define the term plainly, because it gets used loosely.
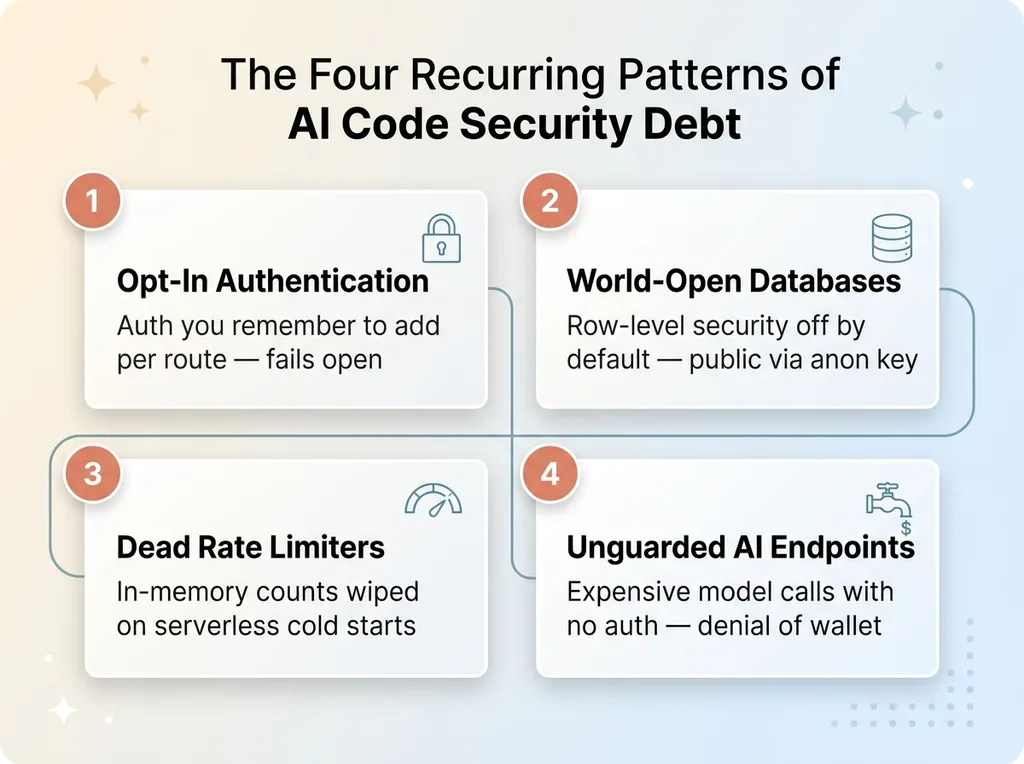 The Four Recurring AI Code Security Debt Patterns
The Four Recurring AI Code Security Debt Patterns
AI code security debt is not "the AI wrote buggy code." It's narrower and more dangerous than that. It's the specific, recurring class of security shortcuts that fast, AI-assisted development introduces because the model optimizes for works in the happy path, not safe by default.
The model writes the route. It does not write the threat model.
Ask an LLM to build you an endpoint that saves a user's data, and it will give you working code that saves the data. It will not, unprompted, ask who's allowed to call this, what happens if they send garbage, or whether this faucet can be left running by a stranger. Those questions live in the threat model, and nobody handed the model the threat model.
This is different from technical debt in the general sense. Most technical debt is ugly: hard to maintain, slow to extend, embarrassing to read. Annoying, but not an emergency.
Security debt is exploitable. It's not that the code is ugly. It's that the code leaves a door open, and somebody can walk through it and read your customers' records or run up your bill.
The good news is right there in the word recurring. LLMs default to the same insecure-but-functional patterns again and again, because they're trained on the same corpus of "here's how you do X" examples that also skip the hard parts. The model is consistent. That consistency is what makes the debt findable. You're not hunting for a unique flaw in every project. You're checking for the same four things.
Pattern One: Authentication Opt-In Instead of Default-Deny
The first pattern is how authentication gets wired.
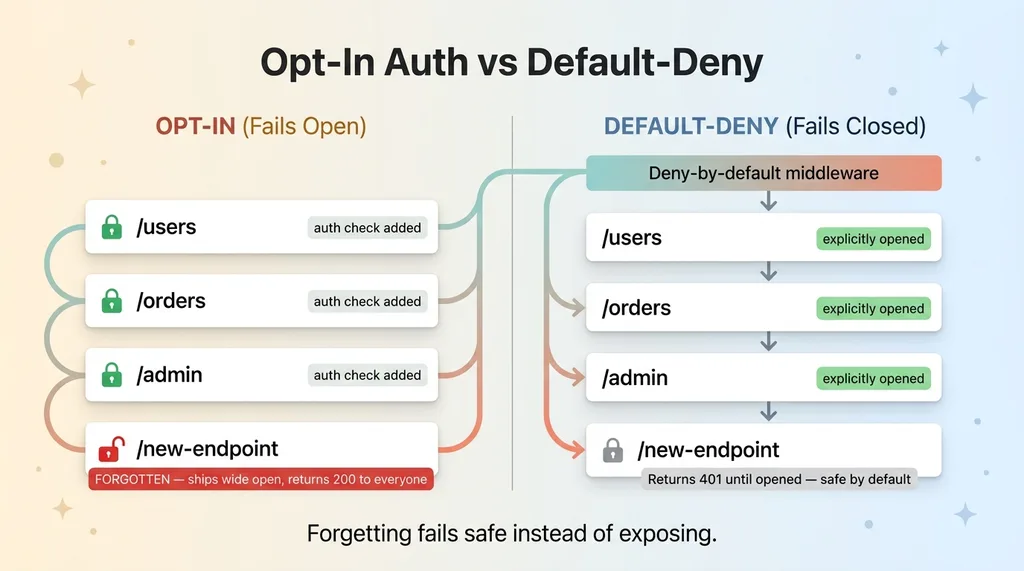 Opt-In Auth vs Default-Deny Comparison
Opt-In Auth vs Default-Deny Comparison
AI-generated code almost always treats auth as something you remember to add per route. You write an endpoint, then you add a check at the top: is this user logged in? If yes, continue. It works. It looks responsible. Every route you've written is protected.
The problem is the next route.
Opt-in auth means security depends on human memory at the moment of writing. The day someone (you, a teammate, the AI on your behalf) adds a new endpoint and forgets the check, that endpoint ships wide open. No error. No warning. It just works, for everyone, including the people who shouldn't have access. The failure is silent and the default is exposure.
Default-deny flips the posture. Every route is locked by default. Access is denied unless a route is explicitly opened. Now when somebody forgets, the failure mode is the safe one: the new endpoint returns a 401 until you consciously open it. Forgetting fails closed instead of failing open.
The fix is architectural, not a habit you try harder at. You put a middleware layer or a route wrapper in front of everything that denies by default. Opening a route becomes a deliberate act, a single explicit line that says "this one is public." Everything you don't touch stays locked.
The difference between these two designs is the difference between "we're secure as long as nobody makes a mistake" and "we're secure even when somebody does." For any team shipping fast, the second one is the only acceptable answer, because the mistakes are not optional. They're guaranteed.
Pattern Two: Databases That Default World-Open
The second pattern lives one layer down, in the database.
Modern app platforms give you a public API key that ships in your frontend. It's meant to. That key is not a secret. Anyone who opens dev tools can read it. The security model assumes that key is public and relies on row-level security policies to decide what each request is actually allowed to see.
Here's the trap: row-level security is frequently off by default. When RLS is off, the table is readable by anyone holding that public key and your project URL. Which is to say, anyone. The key isn't secret, so RLS-off equals public.
I'm not theorizing here. I audited my own work and found that nine of my own databases were readable by anyone with the URL. Nine. Built fast, shipped working, and quietly world-open the whole time.
I tell you that not to confess sloppiness but to make the point that matters: this is the default state of a fast build. It's not a sign you hired the wrong person. It's the gravity of the tooling. The platform makes "off" easy and "on" a thing you have to remember, and AI-assisted code never remembers it for you because the happy path doesn't require it.
The fix is to make RLS-on the non-negotiable default across every table, and to actually test it. Not "we turned it on for the sensitive tables." Every table. Then verify from an unauthenticated client that you get nothing back. I now check this systematically on every build, mine and clients', because finding it later means it was public the entire time you weren't looking.
Pattern Three: Rate Limiters That Do Nothing
The third pattern is the most insidious, because it looks like it works.
 Why Serverless In-Memory Rate Limiters Do Nothing
Why Serverless In-Memory Rate Limiters Do Nothing
You add a rate limiter. The code is right there: track requests per user, block them past a threshold, return a 429. You test it locally, it fires, you move on. Protected.
Except you deployed to a serverless platform, and the limiter stores its counts in memory.
In-memory state on serverless is a fiction. Functions spin up cold, handle a request, and die. There's no shared memory between instances, and the count resets on every cold start. So your limiter is counting requests against a memory that gets wiped constantly and isn't shared across the dozen instances handling traffic simultaneously. In practice it does nothing.
This is the dangerous kind of debt because the code passes review. It reads as protected. The logic is correct. The deployment model silently defeats it. You'd have to know how serverless instances behave to even suspect it, and the AI that wrote the limiter certainly didn't flag it.
This matters enormously the moment money is involved. An endpoint you believe is throttled but isn't, sitting in front of an expensive operation, is a wide-open door wearing a "closed" sign.
The fix is to put rate-limit state somewhere shared and persistent. A managed store like Redis or Upstash, where every serverless instance reads and writes the same counter, or platform-level rate limiting applied at the edge before your function ever runs. Serverless rate limiting only works when the count survives the cold start and is shared across instances. In-memory does neither.
Which brings us to the pattern where this stops being theoretical and starts being a number on an invoice.
Pattern Four: Unauthenticated Endpoints That Burn Your AI Budget
The fourth pattern is specific to AI apps, and it's the one that hits your wallet directly.
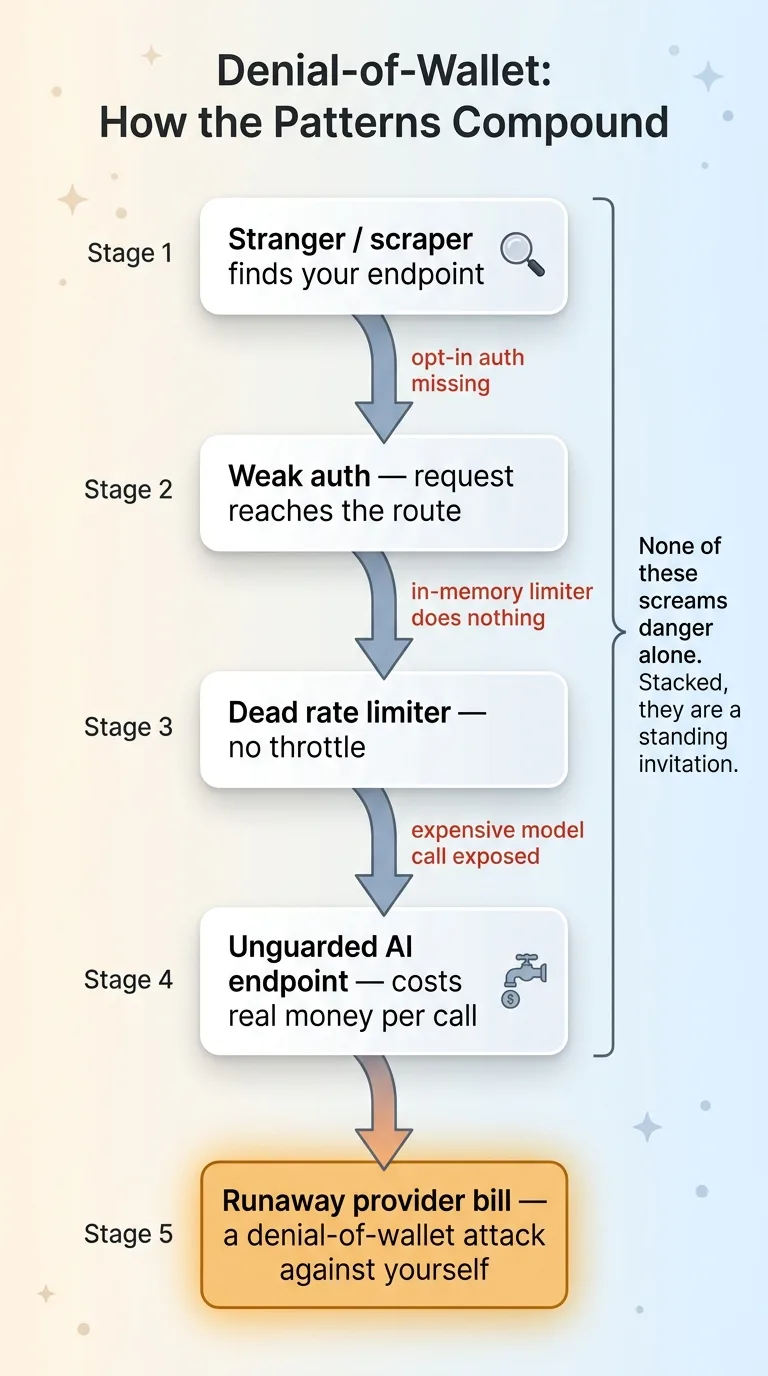 Denial-of-Wallet: How the Four Patterns Compound
Denial-of-Wallet: How the Four Patterns Compound
Picture an endpoint that calls an expensive model. Image generation, long-context analysis, whatever your priciest route is. Now picture it with no auth in front of it and no working rate limit behind it. That's a faucet connected to your bank account, left running, in public.
The attack doesn't need to be sophisticated. A free-tier user who realizes your best generation route doesn't check anything. A scraper that finds the endpoint and hammers it because hammering endpoints is what scrapers do. Each call costs you real money to the model provider, and there's nothing stopping the thousandth call, or the millionth.
This isn't a breach in the classic sense. Nobody stole your data. They just spent your money. The damage shows up as a bill, not a headline, which is exactly why it's easy to ignore until the statement arrives.
The fix has three parts. Auth before any paid model call, so an anonymous request can't trigger spend. Per-user metering, so you know who's calling and how much. And a hard ceiling, a cap that shuts the route down before the bill becomes catastrophic, even if everything else fails.
Notice how these four patterns compound. Weak opt-in auth lets a stranger reach the route. A dead in-memory rate limiter means nothing throttles them. An exposed expensive AI call gives them something worth abusing. Stack those three and you've built a denial-of-wallet attack against yourself. None of the three individually screams danger. Together they're a standing invitation.
You Don't Pay the Tax by Slowing Down. You Pay It With Templates.
Here's where most people draw the wrong conclusion. They look at four exploitable patterns in fast-built code and decide the answer is to go slower. Add review gates. Build less. Treat speed as the enemy.
 Paying Down Security Debt With Reusable Templates
Paying Down Security Debt With Reusable Templates
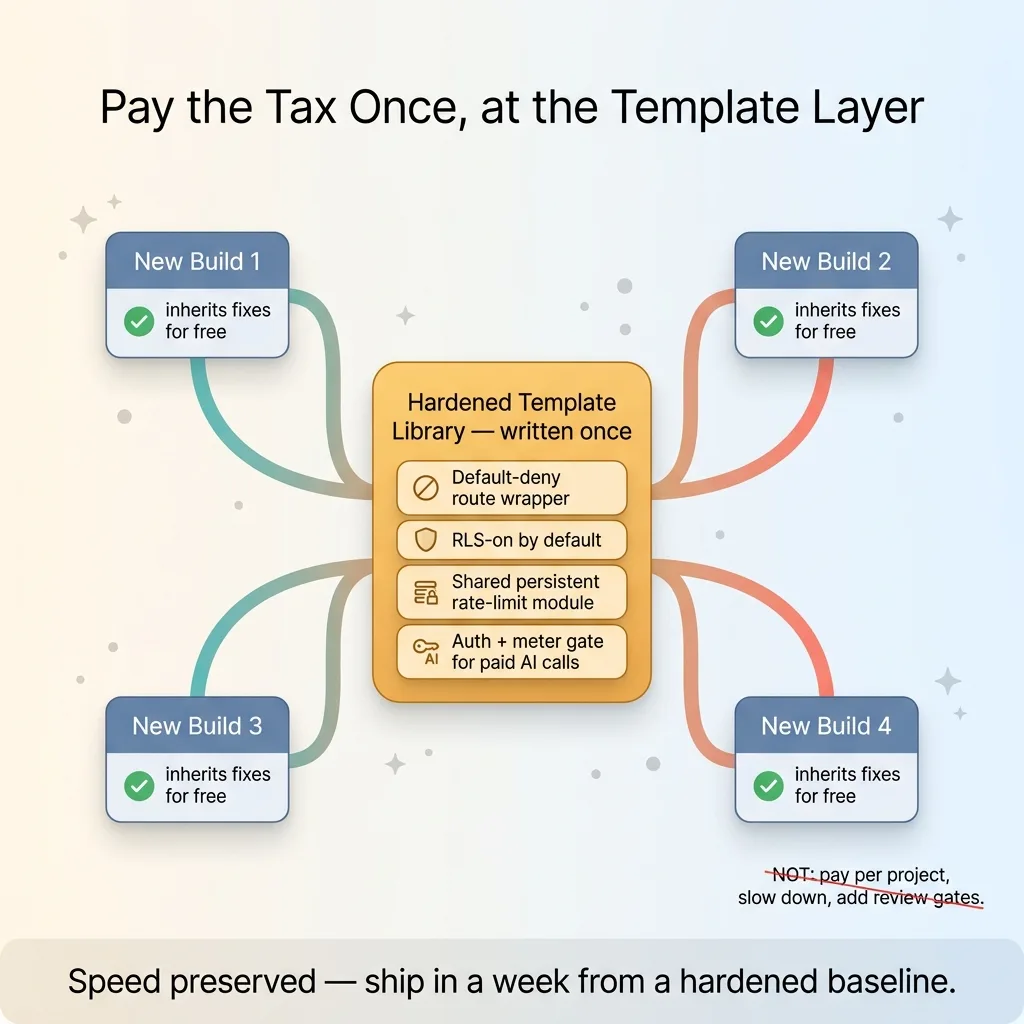
Wrong. Slowing down doesn't address the problem, because the problem isn't your pace. It's that the same four shortcuts recur. And recurring problems don't get solved by caution. They get solved by templates.
Because the patterns are predictable, the fixes are reusable. A default-deny route wrapper you write once and apply everywhere. RLS-on as the literal default when a table gets created, not a checkbox you hope to remember. A shared rate-limit module backed by a persistent store, imported instead of reinvented. An auth-and-meter gate that wraps every paid model call. This is the core of the security trifecta I now apply by default.
Write those four things once and every new build inherits the fixes for free. The speed is preserved. You still ship in a week, but the week's output starts from a hardened baseline instead of a happy-path one. The tax gets paid at the template layer, once, instead of per project, never.
This is also what turns the security debt from a liability into evidence of rigor. I can name the debt out loud, in detail, and I have a written-down way to pay each piece down. That's not a confession of weakness. It's the opposite. It's the same discipline behind why every system I ship stops for a human at the points that matter.
I've seen the same handful of patterns across dozens of audited builds. Same four doors, slightly different houses. Once you know they recur, an audit stops being archaeology and becomes a checklist. That's the whole difference between unmanageable risk and a managed line item.
The Operator Who Names the Debt Is the One You Want
The technical buyer who assumes fast builds are insecure by nature is half right. The debt is real. I've shown you four of its most common forms and I found every one of them in my own work first.
But "the debt exists" is the wrong question. The right question is whether the person who built it can name it, find it, and pay it down systematically. That's the qualification that matters.
Anyone selling you "AI ships flawless code" is lying, and you should stop taking their calls. The honest version is the one I'll give you: I'll tell you exactly where the debt tends to live, because I've dug it out of my own projects, not just talked about it in the abstract.
If you've already shipped fast (and you should, the speed is genuinely worth having) and you want to know what's hiding inside it, that's a specific, finishable job. Bring me in to audit what's already shipped. I'll find the opt-in auth, the world-open tables, the dead rate limiters, and the unguarded AI calls, and I'll hand you the templates that close them for good.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call