AI Code Security Debt: The Tax on Fast Builds
AI code security debt is the predictable cost of fast builds. Here are the four vulnerability patterns that repeat, and the reusable fixes that pay them down.
By Mike Hodgen
Speed Has a Tax, and Most Teams Don't Read the Invoice
I ship fast. My DTC fashion brand pushes dozens of new products a quarter, and behind the scenes I'm running close to 50 repos across the brand and the client work I do. The AI does most of the typing. A product goes from concept to live in 20 minutes when it used to take three or four hours.
That velocity is real, and it's a competitive moat. But it comes with a bill.
Here's the thing nobody tells you when you start building this way: speed creates a predictable, systemic tax. AI code security debt is not a one-off bug you fix and forget. It's a recurring charge that lands on every project you ship, because the tools you're using to move fast all default to the same insecure-but-working choices.
I wrote a confessional piece about this when I audited 12 of my own projects for vibe-coded security holes. That one was the "here's what I found, and it was ugly" article. This one is the prescription. What you actually do about it.
The core insight is this: AI scaffolds pick the option that runs, not the option that's safe. So the same handful of vulnerability classes show up in every project, copied forward through your prompts and your starter templates. Same blind spot, 50 times.
The good news is that the tax isn't paid by slowing down. It's paid with reusable patterns. Fix each class once at the scaffold level, and every future build inherits the fix for free.
In this piece I'll name the four recurring failure classes, the root cause of each, and the template that pays each one down permanently.
Why AI-Generated Code Defaults to Insecure-But-Working
Before I list symptoms, you need to understand the disease. And it's not a model failure. It's a specification gap.
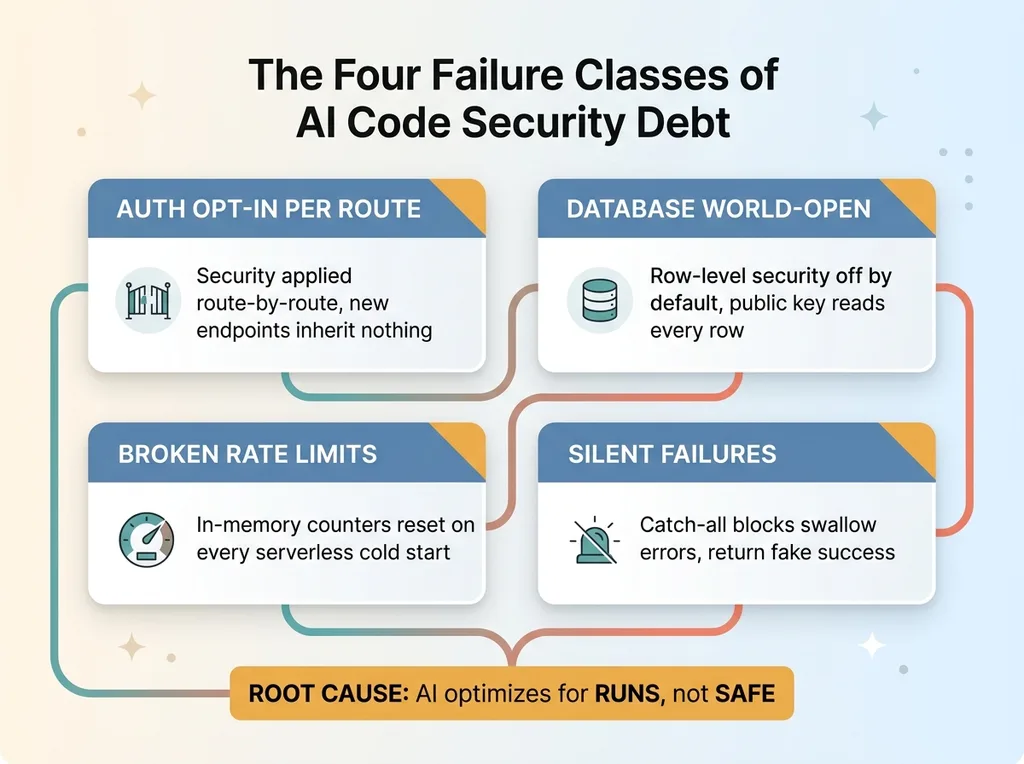 The four recurring AI code security failure classes
The four recurring AI code security failure classes
The model optimizes for 'runs', not 'safe'
When you prompt an AI to build something, you ask it to make the endpoint work, make the query return data, make the form submit. Security is almost never in the prompt, so it's almost never in the output.
The model gives you code that compiles and demos cleanly. Between a secure option and an open one that both satisfy your request, it picks the one that just works. That's usually the open-by-default one, because security adds friction the prompt didn't ask for.
This isn't the AI being lazy. It's doing exactly what you told it. You said "make it work." It made it work.
Insecure defaults are the path of least resistance
The compounding problem is velocity. Once a scaffold pattern works, you reuse it. You copy the prompt, you fork the starter, you carry the same blind spot into the next project and the one after that.
So the question every skeptical buyer asks me is fair: if we move this fast, what predictable holes are we creating?
The answer is four. They're nameable, and the same five security holes show up in every AI-built app I've ever reviewed. Once you know the four classes, you stop being surprised and start building defenses into the foundation.
Let me walk through each one.
Failure Class 1: Authentication That's Opt-In Per Route
Across my repos, this pattern repeats more than any other.
Why default-allow is the silent killer
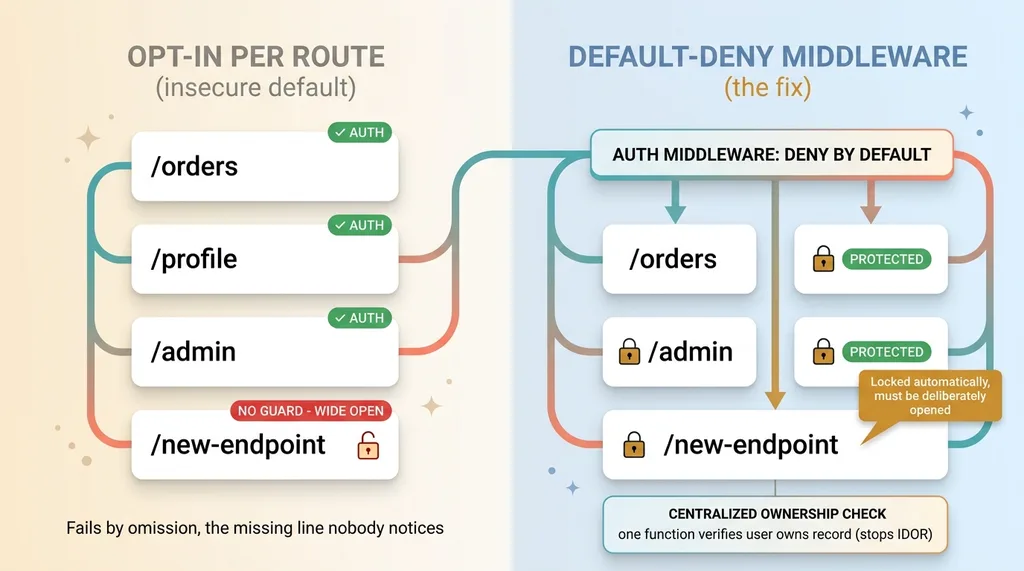
AI scaffolds add authentication route by route, as a decoration you remember to apply. Check the user on this endpoint. Check the user on that one. It works perfectly for the routes you remember.
Then someone adds a new endpoint next sprint. It inherits nothing. No auth check, wide open, and nobody notices because the app still works.
This is opt-in security, and it fails by omission. Omission is the hardest failure to spot, because there's nothing in the code to flag. The vulnerability is the absence of a line, not the presence of a bad one.
There's a related problem hiding underneath it: even authenticated routes often skip the ownership check. The route confirms you're logged in, but it never asks "does this user actually own this record." So I log in as myself, change an ID in the URL, and read your data. That's IDOR, the protection AI developers never think about, and it sits right next to the auth gap.
The fix: default-deny middleware, not per-route guards
You don't fix this by being more careful about remembering guards. You fix it by flipping the default.
 Per-route auth (opt-in) vs default-deny middleware
Per-route auth (opt-in) vs default-deny middleware
Move authentication to the middleware layer so every route is protected unless explicitly opened. Default-deny. Now the new endpoint someone adds next sprint is locked by default, and they have to make a deliberate choice to expose it.
Then centralize ownership checks. Every query that fetches a record by ID runs through one function that verifies the requesting user owns it. One place to get right, one place to audit.
Pay it once at the middleware layer, inherit it across every route forever.
Failure Class 2: Databases That Default to World-Open
This one scares me the most, because the app works perfectly while your entire database is readable by anyone with the URL.
Row-level security off is the same as a public dump
Managed databases with public API layers, the kind every AI scaffold reaches for, ship readable unless you turn on row-level security. The AI rarely turns it on, because the app runs fine without it. The data just happens to be exposed to anyone who finds the endpoint.
Let me make it concrete. The public key that powers your frontend can, by default, read every row in every table. Customer records. Email addresses. Password hashes. All reachable through the same endpoint that makes your app work.
The app demos beautifully. Meanwhile anyone with browser dev tools and ten minutes can pull your whole user table.
The systemic root is the same as before: the secure state requires an extra deliberate step the model never takes. Off is the default. On is the thing you have to know to do.
The fix: deny-by-default policies as a project template
Bake a deny-by-default row-level security policy set into your project starter. Every new table is locked until you explicitly write a policy that opens it.
When I worked through row-level security across 50+ tables, the lesson was that doing it table by table after launch is brutal. Doing it as a template before launch is trivial. The new table inherits the locked state automatically.
Solve it once in the scaffold. Reuse it across every repo. Your data stays private by default instead of public by accident.
Failure Class 3: Rate Limiters That Do Nothing on Serverless
This is the one that costs actual dollars, and it's almost invisible.
In-memory counters reset on every cold start
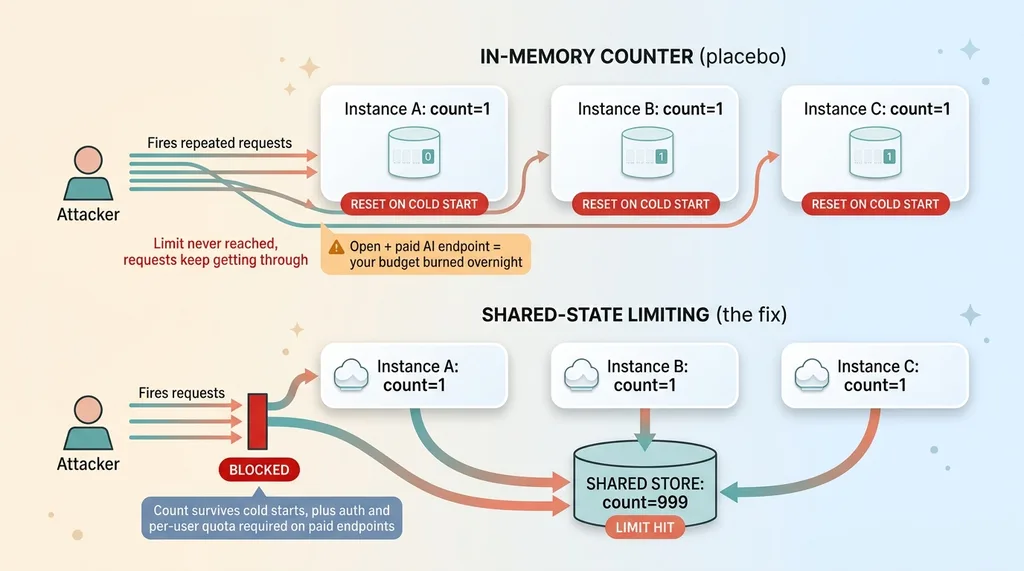
Ask an AI to add a rate limiter and it'll happily build one that stores request counts in memory. Looks correct. Passes a quick test. Ships.
 Why in-memory rate limiters fail on serverless cold starts
Why in-memory rate limiters fail on serverless cold starts
On serverless, it's theater. Every function invocation can spin up a fresh instance, which means a fresh empty counter. The limit resets constantly. Someone hammering your endpoint just keeps landing on new instances with a clean slate.
You think you're protected. You're not. The counter is a placebo.
It gets worse. The most expensive endpoints, the ones that call a paid AI model, are often the ones left unauthenticated, because the demo didn't need a login. So now you have an open endpoint that costs you real money per call, with a rate limiter that doesn't work.
Anyone can hit it in a loop. They can burn your entire AI budget overnight, or farm your most expensive generation endpoint for their own product. This is serverless rate limiting on AI endpoints done wrong, and it's a direct line to your bank account.
The fix: shared-state limiting and authenticated AI endpoints
Use shared-state rate limiting backed by a persistent store, something every function instance reads from, so the count survives cold starts. Then it actually limits.
Add a hard rule: any endpoint that calls a paid model requires authentication and per-user quotas. No exceptions, no "we'll add login later." If it costs money per call, it's behind auth with a ceiling.
I covered this defense stack in detail in the CSP hardening, Zod validation, and rate limiting trifecta. Build it into the scaffold and every paid endpoint ships protected.
Failure Class 4: Silent Failures That Look Like Success
The title of this piece promises a tax on both security and quality, and this fourth class is where the two meet. Quality debt is security debt's quiet twin.
The over-broad catch block that swallows errors
AI loves a catch-all. Wrap the whole thing in a try block, catch any error, log nothing, return something clean-looking. The code never crashes. It also never tells you when it's broken.
I've lived this. A pipeline that reported wins while doing absolutely nothing. A dashboard that showed zeros for two weeks because a token refresh quietly failed and the analytics died, swallowed by a catch block that returned an empty array like everything was fine.
At velocity, this is deadly. Nobody is watching every system every day. The whole point of building this many tools is that they run without supervision. A failure that hides itself can run silently for weeks.
Quality debt is security debt's quiet twin
The root cause is the same pattern wearing a different mask. The AI optimizes for "doesn't crash" over "tells the truth when it breaks." A clean demo with no errors looks better than an honest one that surfaces a problem.
The fix is honest instrumentation. Errors must surface, never get swallowed. Add heartbeats that alert you on silence, not just on failure, because the worst failures are the ones that go quiet.
Set a default rule in your scaffold: no over-broad catch blocks that return success. If something breaks, you hear about it. A quality tax left unpaid becomes a trust tax when a customer finds the broken thing before you do.
Pay the Tax With Templates, Not With a Slowdown
Here's the reframe that makes all of this work. You do not pay down security debt by slowing every project to a crawl. You pay it structurally, once.
Solve each class once, inherit it forever
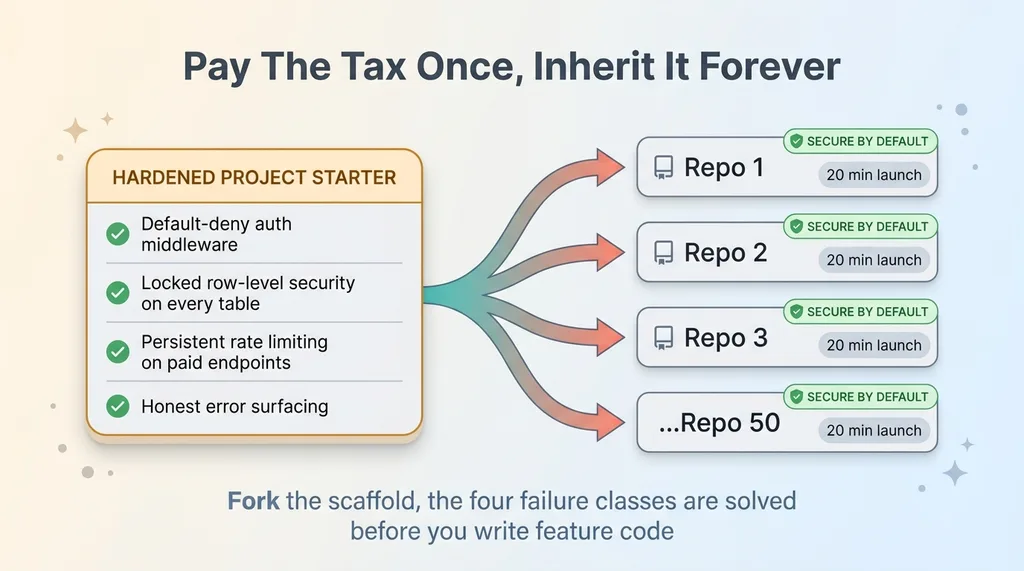
Build a hardened project starter. One scaffold that ships with default-deny authentication at the middleware layer, locked database policies on every table, persistent rate limiting on every paid endpoint, and honest error surfacing instead of swallowed failures.
 Pay the tax once at the scaffold, inherit it forever
Pay the tax once at the scaffold, inherit it forever
Then every new build forks from it. The four failure classes are already solved before you write a line of feature code. Your 20-minute product launch stays 20 minutes. The tax is already paid.
This is the whole trick. Speed and security are only a tradeoff when security is an afterthought. Move it into the scaffold and the tradeoff disappears.
A pre-ship checklist beats a post-breach audit
On top of the starter, run a lightweight pre-ship checklist. Four questions. Is every route default-deny. Is row-level security on for every table. Does every paid endpoint require auth with a quota. Do errors surface or get swallowed.
 The pre-ship security checklist
The pre-ship security checklist
Four checks, five minutes, before a paying customer ever touches the code. That beats a post-breach audit every single time, because the post-breach audit happens after your data is already on someone else's server.
The companies that get this right don't slow down. They build the speed and the safety into the same foundation.
What I Look For When I Audit a Fast-Built Stack
When I come into a company that's been moving fast with AI, these four classes are the first things I check. Auth that's opt-in per route. Databases shipped world-open. Rate limiters that don't survive a cold start. Catch blocks swallowing failures.
I almost always find at least two. Usually three. The pattern is that consistent, because the root cause is that consistent: AI optimizes for working, not safe, and nobody installed the structural fix.
If you're reading this and feeling a little exposed, that's the right reaction, and it's fixable. The answer is not to stop shipping fast. The speed is your advantage and I'd never tell you to give it up. The answer is to install the patterns that make fast safe.
That's the work I do. I build the hardened templates, run the audit across your whole repo set, and hand back a stack that keeps every bit of its velocity without the exposure. The fixes go into the scaffold, so they keep paying off long after I'm gone.
If you've been shipping fast and you're not sure what's underneath it, have me run the same audit across your stack.
Because the companies that win this aren't the slow careful ones, and they're definitely not the reckless fast ones. They're the fast ones who paid the tax structurally.
Want to explore what AI could do for your business?
Book a free 30-minute strategy call. No pitch deck, no sales team, just a real conversation about your operations and where AI fits.
Get AI insights for business leaders
Practical AI strategy from someone who built the systems — not just studied them. No spam, no fluff.
Hodgen.AI
Ready to automate your growth?
Book a free 30-minute strategy call with Hodgen.AI.
Book a Strategy Call